
04.01 update: 代码量很大,目前做大致梳理,后续详细展开
太长不读
推特推荐系统整体流程和业界主流类似,包括召回、粗排、精排、混排等。不过相比非社交主导的内容推荐系统,推特更加重视网络数据(图)的利用,包括图特征、图算法等。并且对负责社交网络内和网络外的模块做了显式的区分和内容控比(目前网络内和网络外占比1:1)。
业务场景
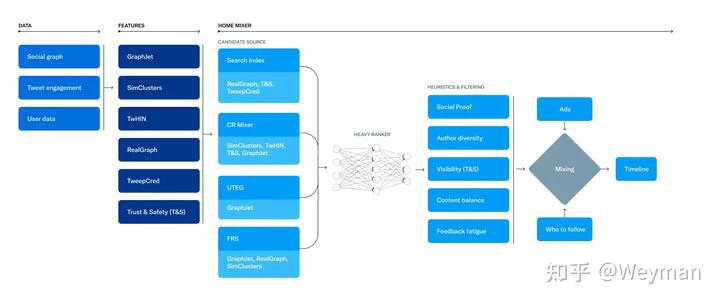
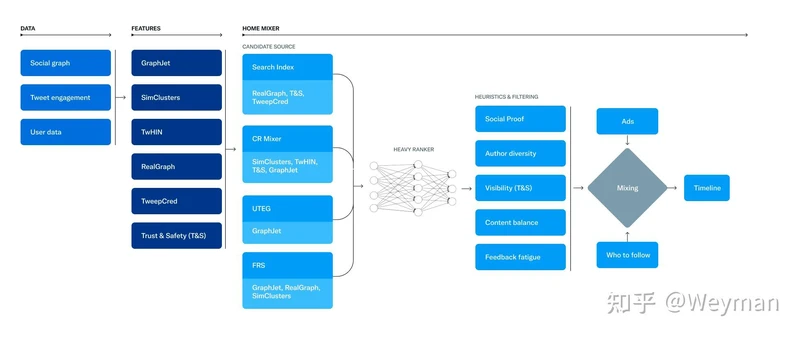
从你关注的人(网络内)和你不关注的人(网络外)中寻找候选人,再对推文、广告、Onboarding prompts综合选出最终展现内容。
推荐系统
- 特征计算
- 社交图谱
- Embedding嵌入(主)
- 偏好预估
- 声誉预估
- 事件流
- 图统计信息
- Trust&Safty
- 违规内容检测————怎么使用?
- 候选&召回
- 社交网络内来源(主)
- 社交网络外来源
- cr-mixer:用于网络外的内容召回,(应该)是一个模型化召回模块
- follow-recommendation-service(FRS):推人服务,提供关注建议Who-To-Follow (WTF)
- 也是一个小的推荐系统,流程基本同主系统,包括候选,排序,过滤,推荐解释
- 其中,排序使用p(follow|recommendation) 和 p(positive engagement|follow) 的加权和
- 过滤&产品功能
- 可见性
- 作者多样性
- 内容平衡(探索利用)
- 基于反馈的疲劳内容
- 二跳人脉过滤
- 替换更新的推文
- 对话
- 同一推文下的上下文组合
- 粗排、精排及多目标
- 粗排(准备重构):
- Earlybird light ranker包括网络内和网络外两个模型,区别在于特征不同
- LR模型;目标是预测用户参与推文的概率(互动)
- 精排:
- 精排条数1500
- 基于神经网络的模型(机器学习部分展开),网络参数48M,特征6k,目标数量10个
- 多目标
- 10个目标,主要包括互动、时长和画风
- 用户喜欢推文的概率
- 用户点击进入此推文对话并回复或点赞推文的概率
- 用户点击进入此推文对话并在那里停留至少 2 分钟的概率
- 用户做出负面反应的概率(要求在推文或作者上“显示较少”,屏蔽或静音推文作者)
- 用户打开推文的概率作者个人资料和喜欢或回复推文
- 用户回复推文的概率
- 用户回复推文并且该回复被推文作者参与的概率
- 用户点击举报推文的概率
- 用户将观看至少一半视频的概率(对于视频推文)
- 简单加权求和(权重看起来像手拍的)
- 主页混排(Homepage Mixer)
- 负责For you, Following, Lists的混排
- 广告、关注推荐Onboarding prompts(?)
- 框架基建
- 推荐流程开销
上面的流程每天运行大约 50 亿次,平均完成时间不到 1.5 秒。单个管道执行需要 220 秒的 CPU 时间,几乎是在应用程序上看到的延迟的 150 倍。
机器学习模块
- 实体抽取
- 基于TransE抽取表征
- 召回模型
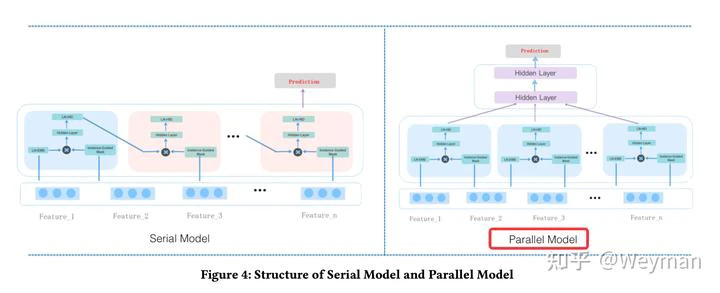
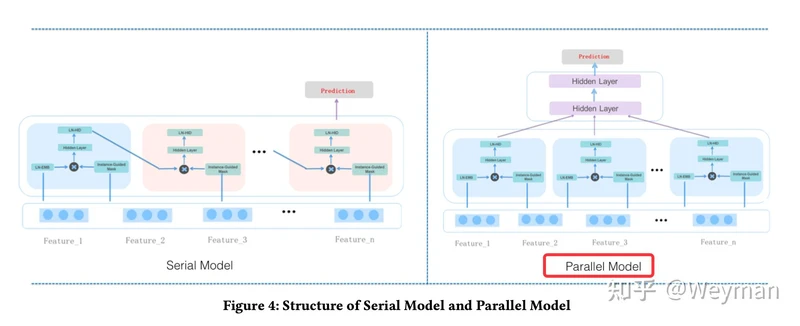
- 粗排模型
- LR: 非常朴素的逻辑回归
- 目标
- 数据流
产品迭代方向
- 为创作者提供更好的 Twitter 分析平台,提供更多关于影响力和参与度的信息
- 提高应用到推文或帐户的任何安全标签的透明度
- 更好地解释推文出现在你的时间线上的原因

