
背景
GameplayTag是GAS中的核心机制之一,它为Gameplay程序员提供了高效的、分层级的过滤及查询等功能,除了技能模块,其他gameplay模块同样可以使用,起到替换hard code的字符串的目的。
本质上,GameplayTag就是带有层级关系的字符串。单机情况下,这样的设计并没有太大的性能问题,因为GameplayTag中的字符串实际上是用FName,底层基于享元设计,共享一个NamePool中的数据。所以同个字符串只占一份内存,包含相同字符串的不同FName实例只是保存了一份FNameEntryId而已。
但在多人游戏下进行网络同步时,FName就会存在一些性能风险:因为FName是可以动态注册创建的,底层的享元只是在单个进程,所以不能保证Client和Server的全局FNamePool是完全一致的(这点很关键),这意味着通过网络传输的时候FName的流量消耗就等同于FString,直接于字符数量成正比。这样处理显然不能获得理想的性能。
基于上述问题,UE为GameplayTag提供了几种优化机制,但这些机制并不全都是开箱即用的,我们需要根据项目实际配置的Tag以及业务使用情况,针对性的提供一些先验信息,更进一步的实现网络流量的最优化。
整体上来看,引擎默认提供优化机制包括以下几种:
- Fast Replication
- 根据Tag数目缩短NetIndex长度
- 根据使用频率优化NetIndex分配
后续引擎源码均为5.2.0-release版本,Tag配置等项目内容来自Lyra
1. Fast Replication
前文提到,FName之所以网络传输时会作为字符串,而不是FNameEntryId进行传输节省流量,是因为Client/DS两端的NamePool是不一致的,会受到实际需求,执行顺序等多种因素干扰。
但是GameplayTag不一样,整个游戏会出现的全部GameplayTag类型是确定的。尽管可以在runtime动态传入一个字符串去请求创建一个GameplayTag实例,但是需要Tag是已经配置在ini(一般是DefaultGameplayTag.ini)中,在TagManager初始化注册过的,否则就会请求失败。
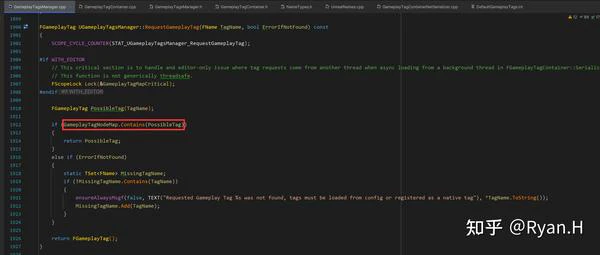
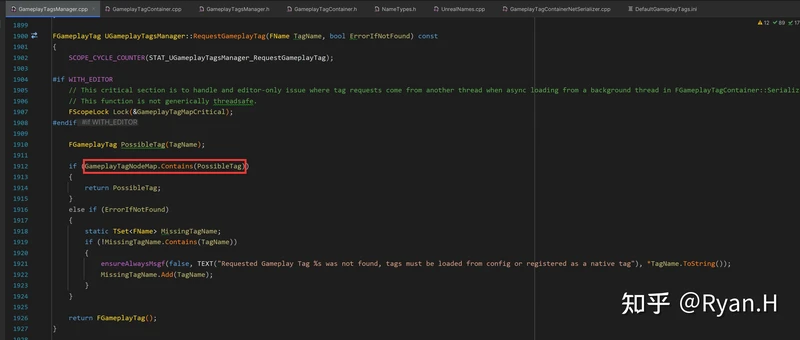
所以只要通信双方的GameplayTag数目和定义顺序一致,就可以使用一个NetIndex(uint16)替代原本的字符串进行传输,对方收到信息后反序列化时,使用这个Index去查询GameplayTagNodeMap,转换成为GameplayTag即可。
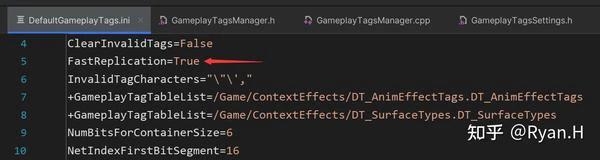
视角回到源码,该优化开启与否的分支位于FGameplayTag::NetSerialize()网络序列化函数中,启用只需要在DefaultGameplayTags.ini中配置FastReplication=True即可
1.1 先决条件
开启这个优化的前提条件的很容易被人忽略,就是DS和Client的GameplayTag的内容、数量和定义顺序保持一致。这个要求看上去不难实现,DS和client同时间打包即可,但实际上在后续运维过程中还是有一些值得注意的点的。
举个例子:发Patch热更的时候,如果有对Tag定义的修改,就需要两端一起Patch。对于单局对战类的游戏这可能也不是什么大问题。但对于一些需要不停服滚服更新服务器,可能同时存在多个不同版本的DS配置的游戏,例如大世界类型的,就需要格外注意两端的Tag一致性了。
1.2 性能开销
由于序列化的过程变得稍微复杂了一些,所以也需要分析一下带来的额外CPU和内存消耗。
相较于原版,这里在每次同步时多出来的操作是:
- 序列化时:通过Tag查找其对应的NetIndex
- 反序列化时:通过NetIndex查找其对应的Tag
所以内存上,我们需要两个长度为Tag总数的Map,长度最多不超过65536(uint16最大值),分别为以Tag/NetIndex作为Key和Value。
这两个Map的构造可以在初始化的时候进行,每次序列化时一次Map查找,整体开销非常低,不用多虑。
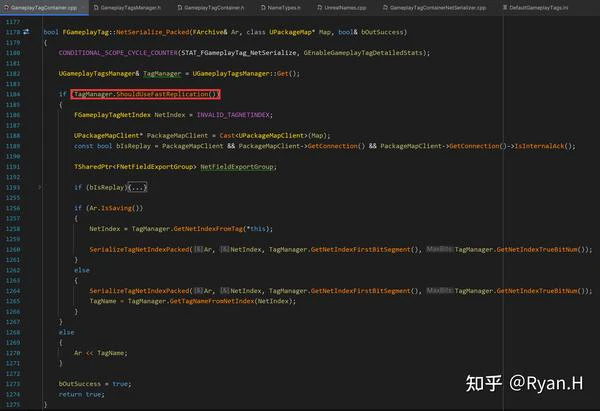
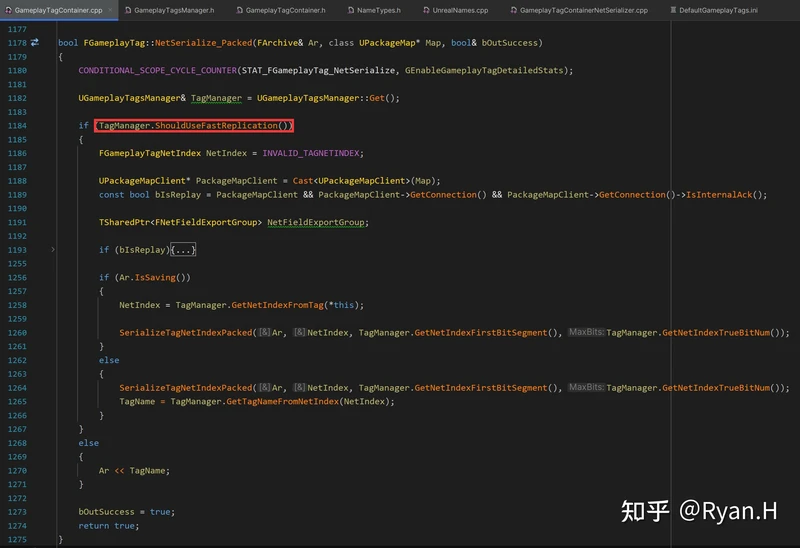
引擎中的实际实现如下。
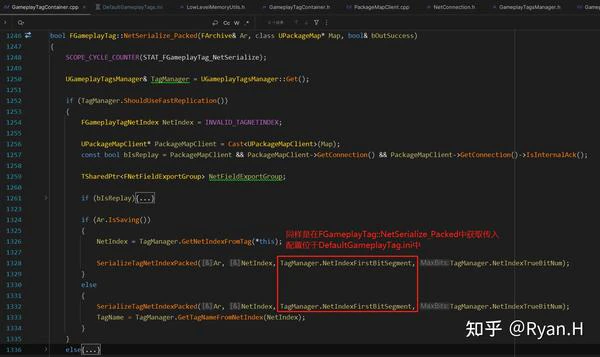
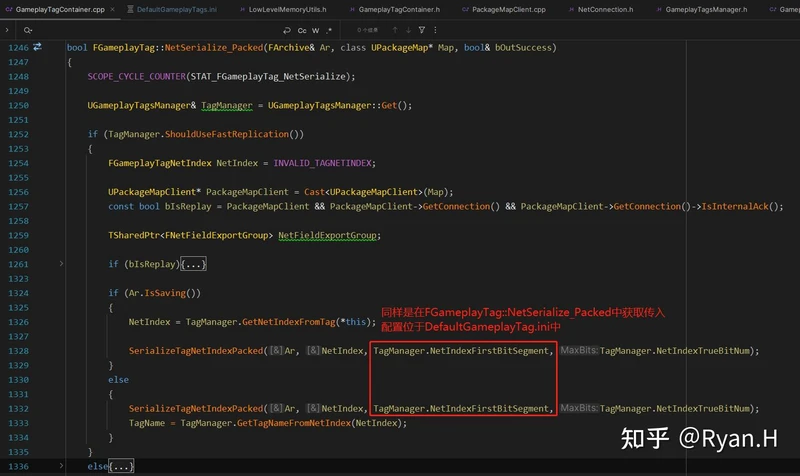
在序列化时:
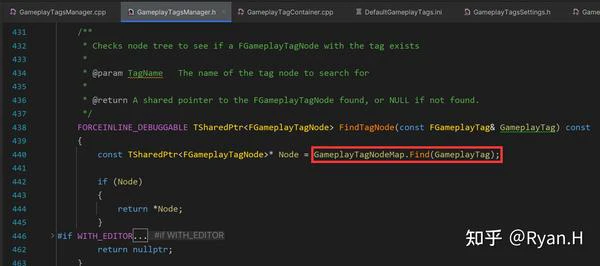
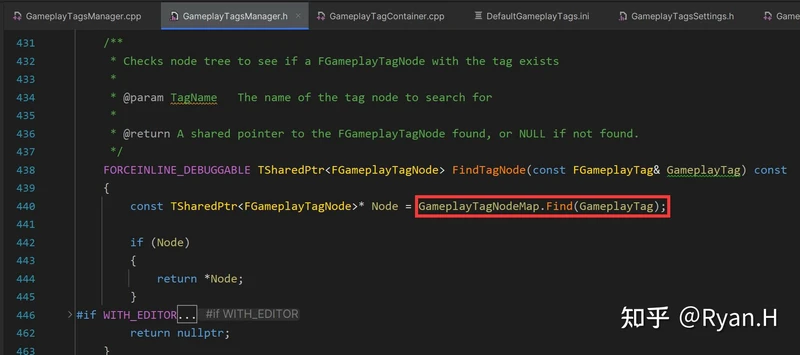
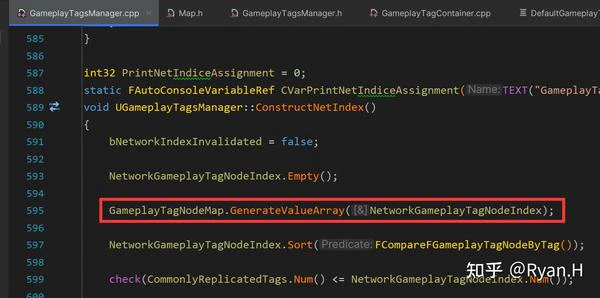
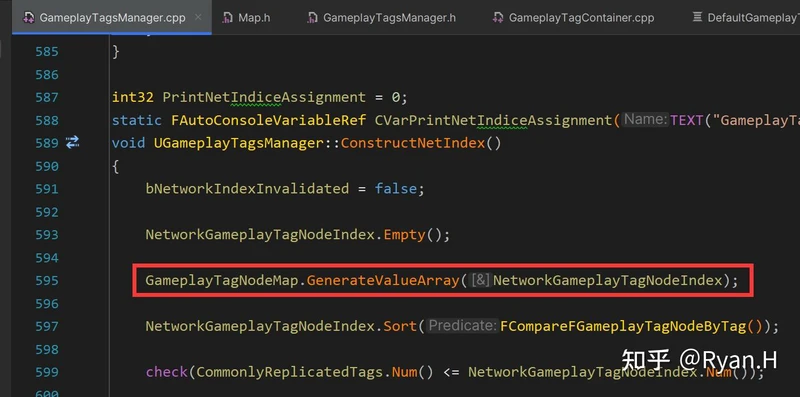
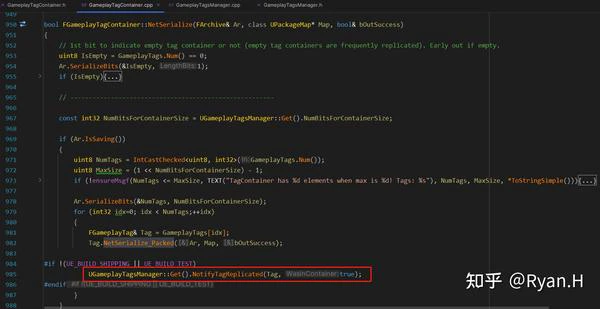
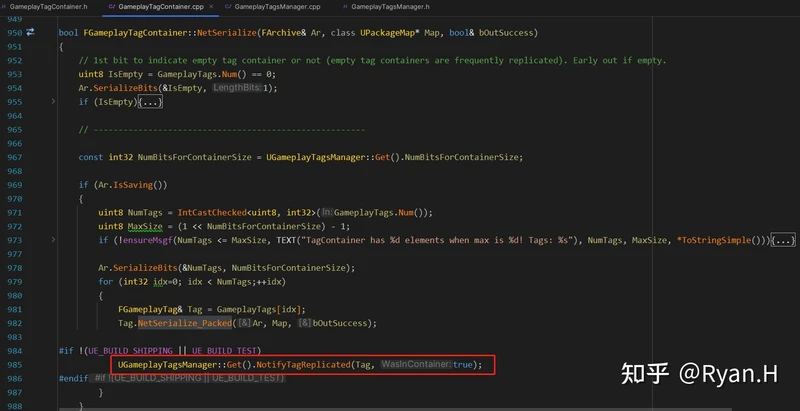
从Tag获取NetIndex时调用的关键函数是下图中的FindTagNode,GameplayTagNodeMap分别记录了Tag和其在层级树中所对应的Node,而NetIndex信息就在Node结构体中。
GameplayTagNodeMap是在GameplayTag初始化时,按照下述这个栈帧添加进元素的。
- ConstructGameplayTagTree
- AddTagTableRow
- InsertTagIntoNodeArray
- GameplayTagNodeMap.Add
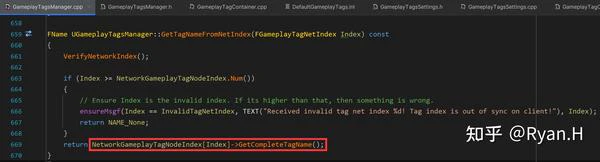
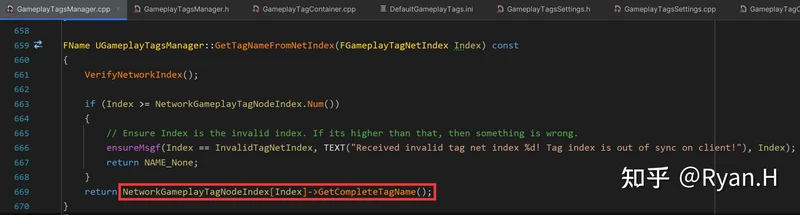
在反序列化时:
反序列化的处理相比序列化时要稍微复杂一些,其中最关键的结构体NetworkGameplayTagNodeIndex,其实就是序列化时的GameplayTagNodeMap中所有Value单独提取出之后,之后按照Tag层级进行排序(即在一个数组中存储一个树状结构)得到的。这一步是首次进行GameplayTag网络同步时候惰性执行的。
这里排序其实不是必须的,因为Client与DS上,GameplayTagNodeMap这个Map中的创建过程和元素都是相同的,即使有Rehash只要两端Map的内存增长和分配策略一致,最终的实际的分布顺序也是一致的。排序的实际目的与后续另一项优化相关。
1.3 最终效果
启用Fast Replication后,GameplayTag单次同步的消耗变为与Tag中字符串长度无关,降低(也可能是增高,如果你的Tag不超过两个ASCII码的话...)至一个FGameplayTagNetIndex的大小,也就是16个bit
2. 根据Tag数目缩短NetIndex长度
在开启Fast Replication之后,我们单个Tag的同步开启来到了16bit,那么这16个bit还有没有优化空间呢?
显然还是有些水分的。
FGameplayTagNetIndex作为一个uint16,可以放下65536个不同的Tag类型,对于绝大多数的项目这个数目绝对都是远远过剩的,既然Tag数目是已知且确定的,只需要传输刚好放得下所有Tag的Bit就可以了,16bit的没用完的高位必然是0,没有传输价值。
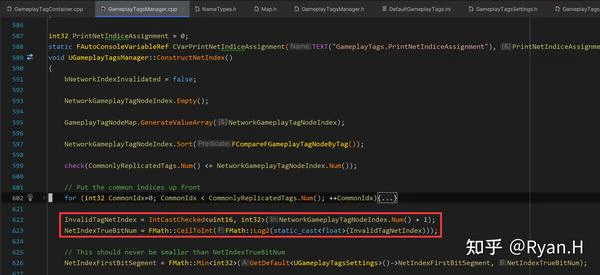
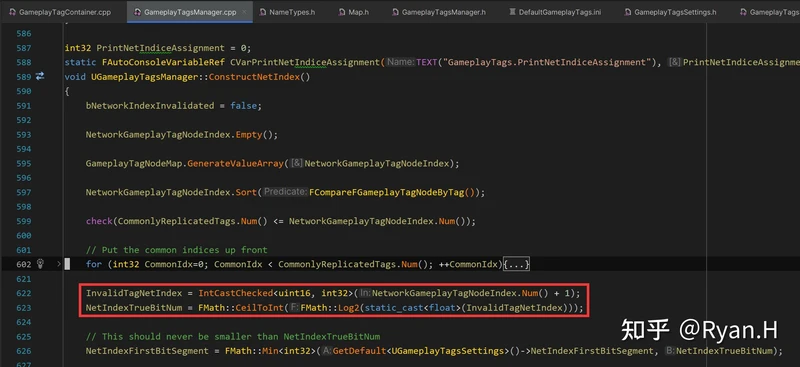
假设Tag总数为N,只需要CeilToFloat(log2 ^ N)个bit,就足以区分所有的Tag了。所以在TagManager初始化,注册所有ini中定义的tag时,记录总数然后计算得到所需要的bit数,然后传输时按这个格式序列化/反序列化即可。
结合具体源码去看,其初始化同样是在构造NetIndex时,获取整个数组长度并对2取对数,然后在序列化时使用该长度,而不是16。
2.1 & 2.2 先决条件&性能开销
这里的先决条件和开启Fast Replication相同,在每次同步时也没有什么重度的性能开销,只是函数多传一个参数,所以也就不再过多分析了。
2.3 最终效果
视项目Tag数目而定,一般而言可以优化5-6个bit,减少30%-40%的Tag同步流量消耗
3. 根据使用频率优化NetIndex分配
在执行完上述的两点优化后,GameplayTag同步流量消耗已经达到了一个比较良好的水平。但毕竟UE不是一般引擎,在此基础上又更进一步,给出了一套基于频率的优化方案。
这个方案基于观察分析,做了这样一个类似28定律的假设:
不同Tag的同步频率存在很大的差异,少部分高频同步的Tag消耗了大部分的流量。
首先宏观来看,对于所有Tag的总流量消耗,假设共有N种Tag,最终总的数值是:
Total Data = \sum_{0}^{N}{TagData_{n}} = \sum_{0}^{N}{(TagData_n * TagFrequency_n)}
基于假设,我们肯定是要尽可能的降低 TagFrequency_n 比较高的Tag类别的消耗,因为这些Tag近乎决定了整个Tag的流量消耗。
拆开来看,高频次可能是使用不当,也可能是业务需求,在引擎层面这个问题不得而知,需要使用者自行分析;显然应该想办法从单次消耗入手,那方向也就显而易见了:降低高频Tag单次的同步消耗。
截止到这里,我们对于所有Tag都是一视同仁的。Tag对应的NetIndex是由这个tag被程序员添加进DefaultGameplayTag.ini的先后顺序和他们本身的层级(Sort时使用)决定,这只是一个没有什么额外信息的整数。既然NetIndex的实际数字没有任何意义又一直在传输,我们是不是可以给这个数字赋予一些先验信息,使其拥有更大的信息量,从而达到总体的最优呢?
我们的目标是降低高频Tag单次的同步消耗,分析这个命题:
高频同步的Tag单次传输的消耗尽可能的低
\Rightarrow 高频Tag对应NetIndex对应的bit数目尽可能的少
\Rightarrow 高频Tag对应的NetIndex的数字尽可能的小
理论分析到这里就告一段落了,带着这个方案来看一下UE给出的工程实现。
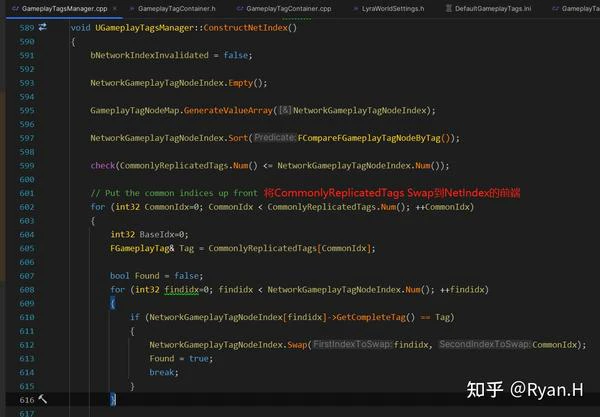
首先,UE直接将Tag划分为了高低频的两种;
- 对于高频Tag,为其分配尽可能小的NetIndex,使用更短的长度bit进行同步,降低总消耗
- 对于低频Tag,还是全量同步
但这并不是完全Zero Cost的,因为我们引入了新的信息:Tag的使用频率高/低。这个信息也需要放到我们同步的数据中,否则反序列化的一端就不知道我到底该反序列化多少个bit,所以我们还需要一个额外的bit的去区分这个Tag是高频还是低频的,进而决定要序列化多少个bit长度的数据。这也正是只区分高低频,而不是继续往下细分下去的根本原因。
结合源码来看,UE提供了一个可配置的参数NetIndexFirstBitSegment和一些在Dev环境下统计和自动计算最优解的GM。
NetIndexFirstBitSegment参数的含义是我们打算用多少个bit来传输高频的Tag。在序列化时这个数值和优化2中的计算得到的Tag实际数量一起传入,显然这个参数的最优值,直接和项目中和高频Tag数量相关。
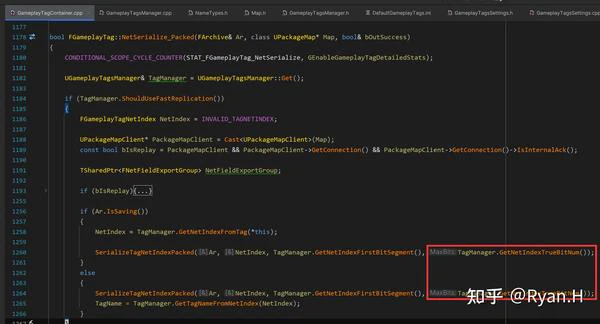
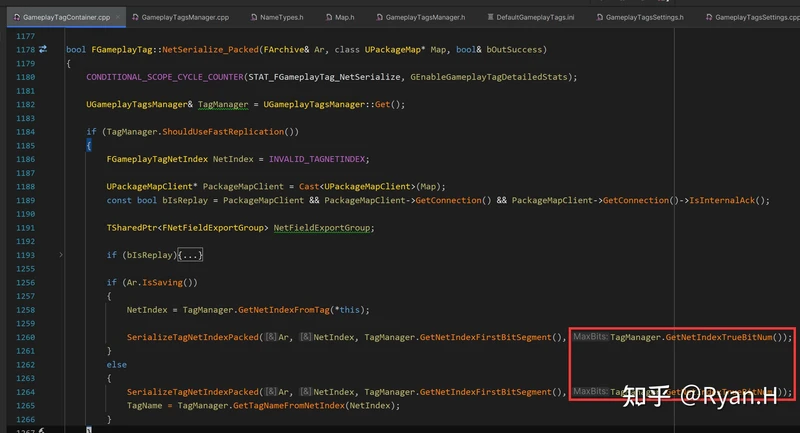
具体的使用点和处理过程可以参考下图中的描述
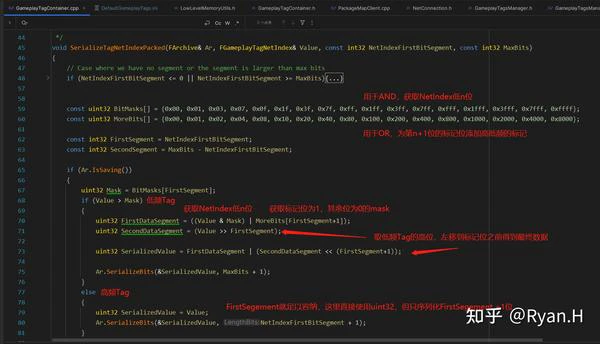
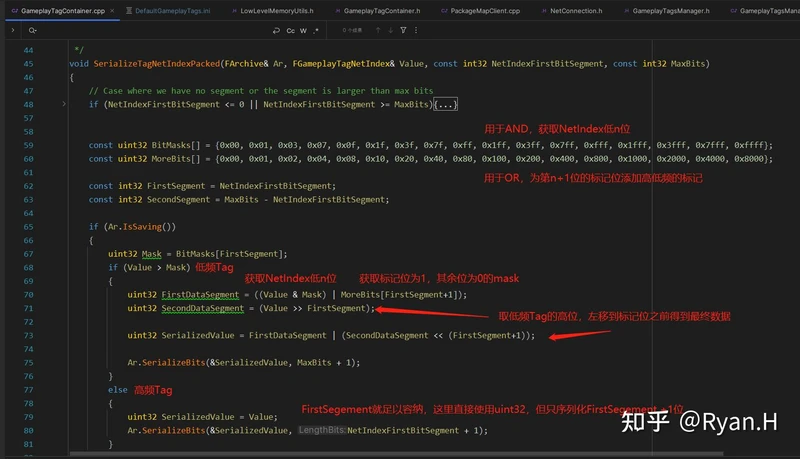
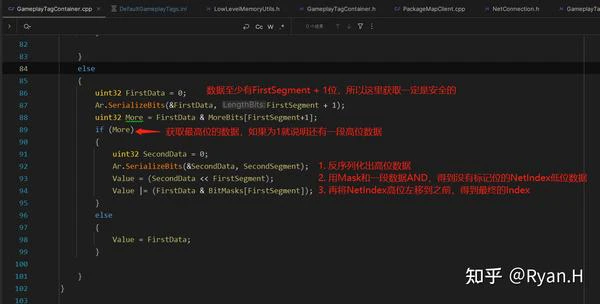
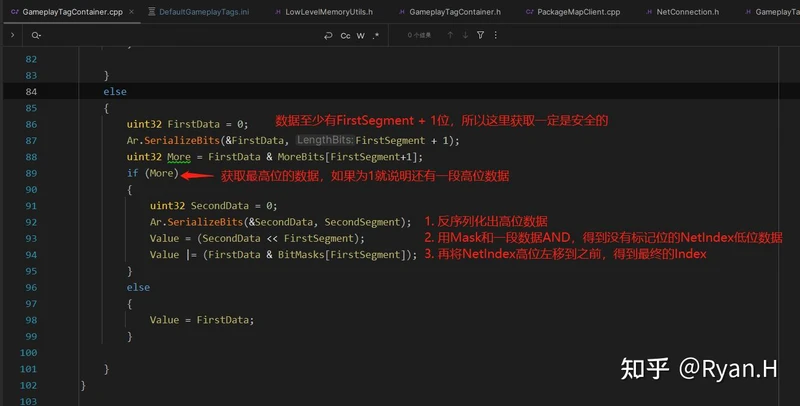
可以看到为了保证高效的CPU计算,这里序列化和反序列化时都使用了直接在栈上分配的Mask和More的Bit数组内存,然后使用了一些看起来很吓人的位运算。实际上我们只要了解最终的数据Layout,这里的内容就很容易看懂了。举个例子,假设我们的FirstSegment为6bit,Tag总长是10bit,现在有两个Tag,NetIndex分别为55(< 2 ^ 6, 高频)和262(> 2 ^ 6,低频),我们将其转换为二进制来看
其实还是很容易搞清楚的。在了解了这些背景和处理之后,我们又迎来了新的问题:那么该如何选择这个数值呢?
再回看上面的总流量消耗的推导:
Total Data = \sum_{0}^{N}{TagData_{n}} = \sum_{0}^{N}{(TagData_n * TagFrequency_n)}
优化前,显然 TagData_n 是一个常数,我们记为D;
\Rightarrow \sum_{0}^{N}{(D* TagFrequency_n)}
优化后可能存在两种情况,全长的D+1或者是我们配置的FirstSegment + 1,我们记为FS + 1,进而
\Rightarrow \sum_{0}^{N}{(HF*(D+1) + (1-HF) * (FS+1)) * TagFrequency_n},这里HF\in 0,1, FS\leq D
在我们通过测试得到了一组具有代表性的TagFrequency数据之后,就变成了一个以FS为变量的方程,分别代入不同数值找到一个最小值即可。
实际上,贴心的UE连这一步也帮你做了,可以参考SerializeTagNetIndexPacked函数上这段注释


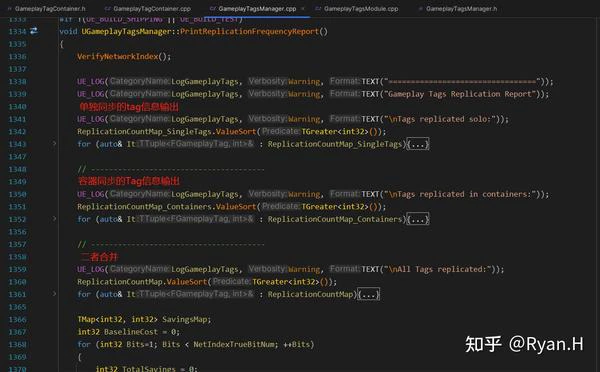
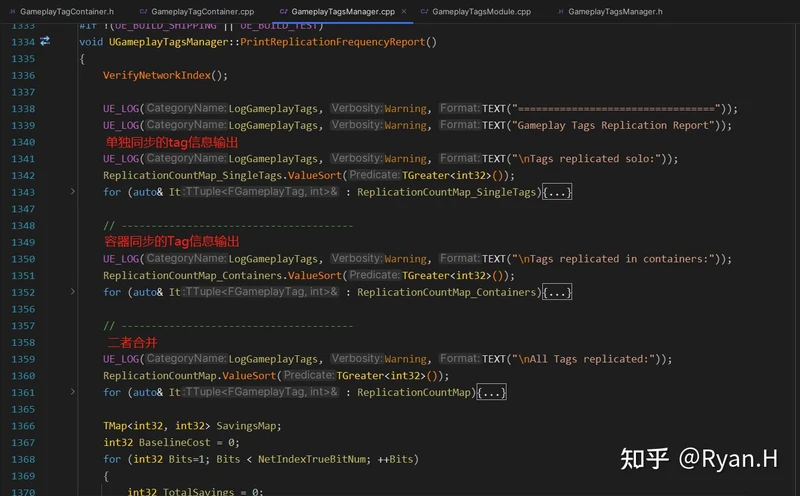
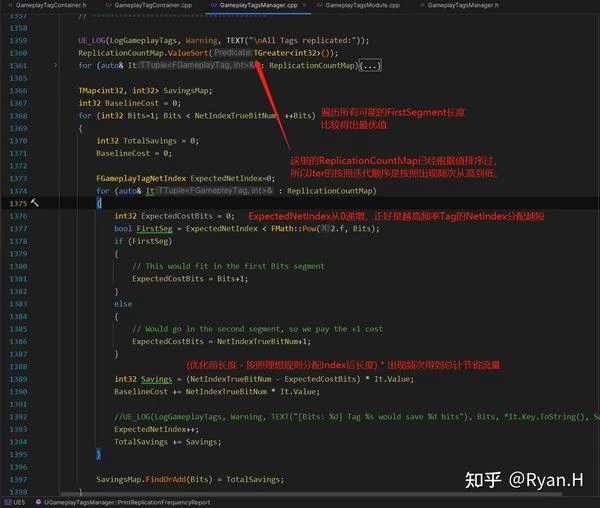
在自动化统计并且输出最优配置值的实现上,UE在非Shipping build下的两个GameplayTag同步点都加了打点,这两个打点只有是否通过容器的同步的区别,分别被记录到不同的容器中。
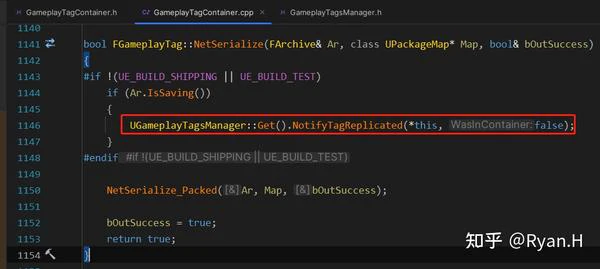
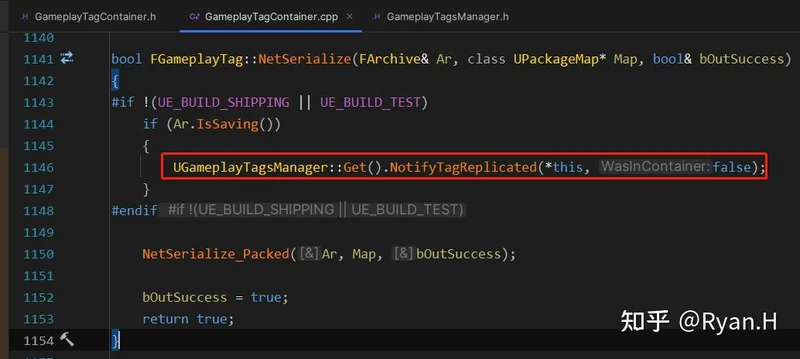
在计数之后,在调用指令:GameplayTags.PrintReport时,首先分别输出几个收集完毕的容器中的数据
后续的这部分计算是统计的核心目的,没有用到什么奇技淫巧,直接暴力遍历计算了所有的可能性,然后分别输出优化的流量数量以及Baseline,得到针对这个测试用例下的最优长度配置。
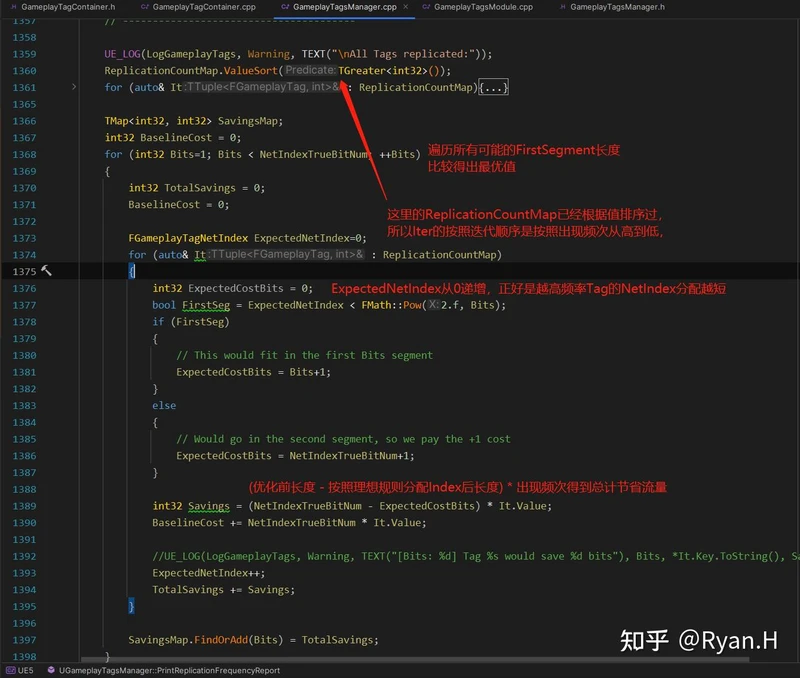
最终,会根据结果直接输出一份完整的,可以直接复制粘贴到DefaultGameplayTags.ini中的最优化配置list。
其实这里的配置深究一下也是有点意思的,UE并不是沿用原来的+GameplayTagList="A.B.C"这种格式,然后要求你把所有Tag都按照频率顺序排序完填进去,而是单独给出了一个+CommonlyReplicatedTags的前缀,在初始化构造NetIndex时优先构造这部分Tag。

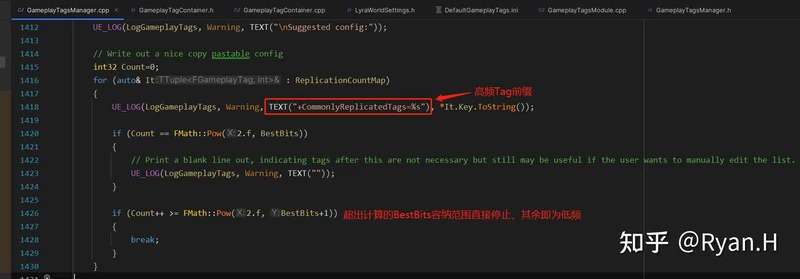
这么处理的好处其实就是不用大规模改动原先已有的配置顺序了。因为不同Tag的同步频率实际上会伴随着业务的开发不断变化,所以需要定期测试更新高频TagList,这时候不用全部重排,就方便开发人员自行手动调整一些测试用例可能cover不到的case
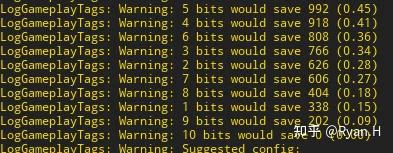
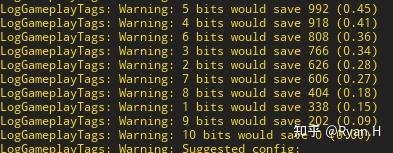
最终的输入类似类似下图,给出不同长度的节省的总的bit数量以及与baseline对比的百分比,这里只是我随便测试了一下得到的结论,实际项目中应该不可能到这个比例。
3.1 先决条件
项目中的Tag复制频率真的满足假设:
即少部分高频同步的Tag消耗了大部分的流量
3.2 性能开销
在每次Tag同步时,额外开销就是之前分析过的位运算的那部分。
对于高频Tag,复制时只是在首位多留出了一个0,逻辑上和优化前基本没有区别;
对于低频Tag,通过位运算在其中插入了一个1,C++直接通过位运算操作内存的效率无需置疑,不必多虑;
整体上,引入的只是系统复杂度,性能开销是很可控的
3.3 最终效果
需要结合项目实际数据分析,甚至可能是负优化
3.4 One More Thing
其实上文中有一点被我选择性忽略掉了,就是要怎么测试得到一个有代表性的数据。
引擎中的描述是"Run a normal networked game on non shipping build" ,一开始看到时候感觉有点扯淡,这不是什么也没说,但细想过后才品味出一点点深意。
从众多数据中选取出一条有代表性的,属于是统计学的范畴;但众所都周知,统计学中的代表性这个metric,可操作性很强。
代码读到这里的时候,联想起当初还在炼丹的时候在西瓜书看到的第一条定理:NFL(No Free Lunch)。我们选取一个最优的频率分布,其实和NFL选取最优的算法是一样的;只要输入是任意的,就必然不可能有一个最优的分布使得所有case下它都是最优的,一定可以构造出一些负优化的case来。
比如玩家如果就只使用低频Tag相关的功能,这种情况下它还是真的"低频"么?
所以再回过头看注释中的这个"normal",其实就是说选一个最正常的的case。因为不存在一个全局最优频率分布情况,所以就不必钻牛角尖,只要绝大多数情况下有优化即可;一昧的追求提升幅度反而可能导致对另一个部分玩家变成一项负优化,这就有些舍本逐末了。
后记
终于写完了,可以没心理负担的等着玩星空了

