
思路:通过笔记(二)中代理的设置,已经可以对YouTube的信息进行爬取了,这几天想着爬取网站下的视频信息。通过分析YouTube,发现可以从订阅号入手,先选择几个订阅号,然后爬取订阅号里面的视频分类,之后进入到每个分类下的视频列表,最后在具体到每一个视频,获取需要的信息。以订阅号YouTube 电影为例。源码请点击这里。
一、爬取YouTube 电影里面的视频分类列表
打开订阅号,我们可以发现订阅号下有许多视频分类如下图所示,接下来可以解析该订阅号信息,把视频分类的URL和名称爬取下来。
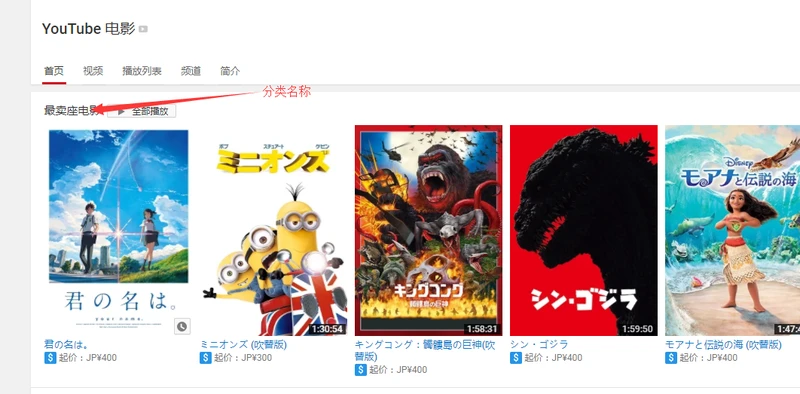
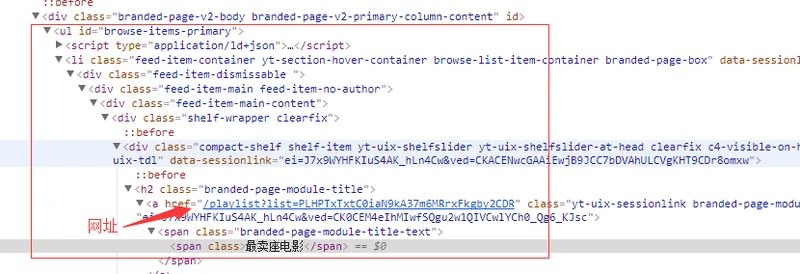
接下来我们通过浏览器点击检查查看网页,分析下如何获取分类,可以发现所有的视频分类都在ul 下的 li 里面,通过ul的id 我们便可以找到分类的相关信息,因此我们可以利用cheerio模块来解析页面,从而获取分类信息。
先将获取分类信息的相关代码分装成一个函数function categoryList (url , callback){},代码如下:
接着调用categoryList函数:
在后台运行就得到了视频分类信息,这是会发现视频分类里面又包含了某些订阅号,而我们只需要提取视频分类。
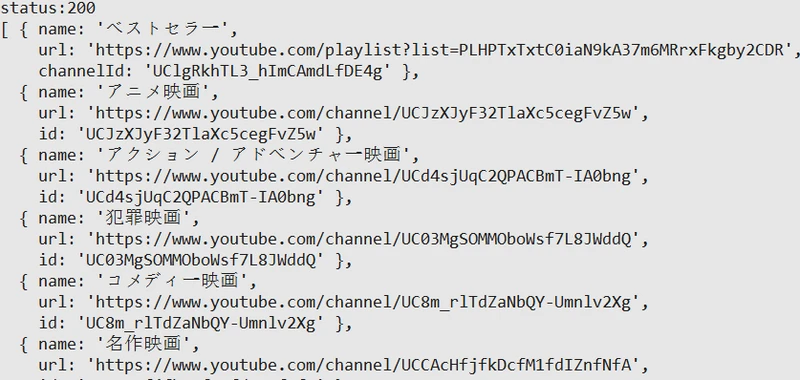
去除订阅号信息(当然也可以添加到订阅号列表,然后再依次读取订阅号下的视频分类)
这时再运行会发现订阅号的信息已经剔除了,只保留了分类列表,接下来进入到下一层,通过视频分类获取视频列表。
二、获取视频列表
我们以最卖座电影为例,获取其下面的视频列表。点击打开页面,我们会发现该分类下视频列表全部在在里面,我们同样只获取其url 以及名称等信息。
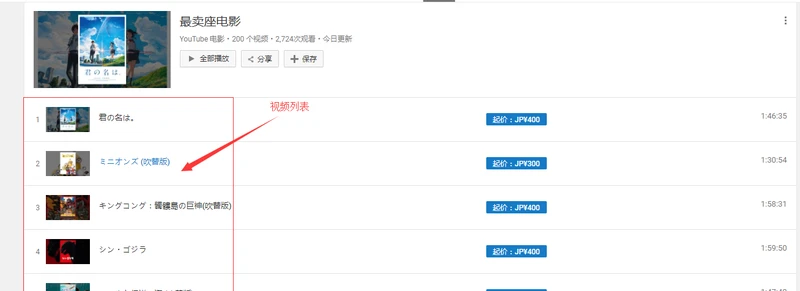
点击检查(ps:我用的Google浏览器),先查看下网页结构,再用cheerio进行解析。检查发现我们可以通过tbody中的tr获取每个视频。

相关代码如下:
运行后我们可以发现后台打印出了视频列表的想关信息
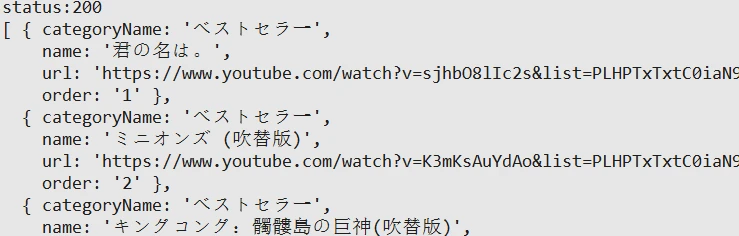
三、获取具体视频信息
以第一个视频为例,点击可以看到发布时间,简介等视频信息多可以提取出来。
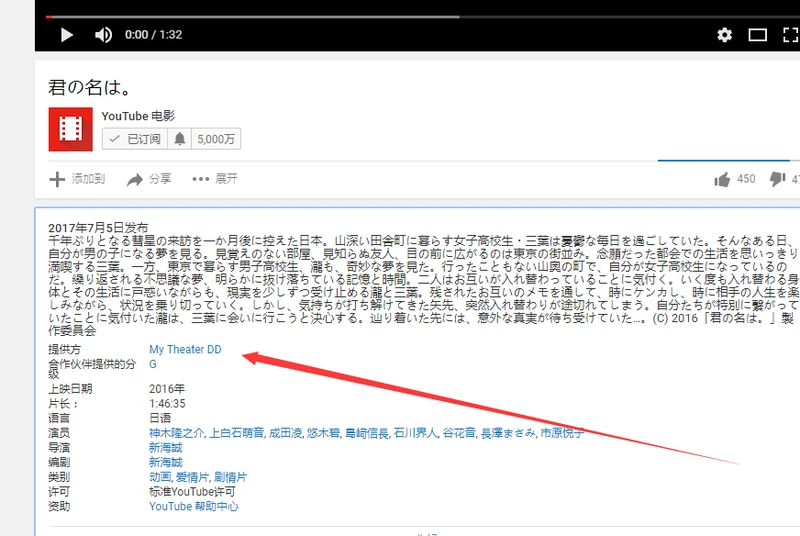
同样通过检查,分析页面后,我们的代码如下:
运行后发现视频的部分信息已经打印出来啦!

到这我们已经完成了从订阅号到视频分类再到具体视频的一整个过程,接下来我们利用nodejs爬虫笔记一中的方法对其进行保存。
四、整理并保存
1、首先在youtube目录下新建config.js、read.js、save.js以及index.js文件,config文件用于存储订阅号网址等信息,read文件用于读取页面信息,save文件用于将数据存储在mysql,index作为主文件,通过调用read和save文件运行,将信息依次保存。
2、安装相关模块,如mysql,debug,async等。
3、 在数据库中,新建YouTube数据库,分别新建channel,categroy,video和information四个数据表,依次保存订阅号信息,分类列表,视频列表和视频信息。
4、因为每个视频对应着唯一的ID,因而对得到的视频列表进行去重处理,然后再到具体的视频,以免获取重复的视频信息。
config.js
read.js
save.js
index.js
最后设置环境变量,debug= youtube:*(ps:Windows下为set debug=youtube:*),并在youtube目录下执行node index,命令窗口将会依次打印出相关信息。
五、小结
通过本次练习,加深了对nodejs爬虫的理解,已经相关模块的应用,但通过爬取的信息,我们可以发现网站中有很多加载更多,而里面的内容我们并没有爬取下来,只爬取到了没点击加载时的页面信息,接下来得好好琢磨如何获取加载更多的内容。

