
本文原发于2019年3月,误删,故重发于2019年5月23日。
全文的组织结构如下:


Part 1. 数据获取
1.1 数据集简介
该数据集是YouTube平台上Trending List中每日的视频信息统计,包括视频的标题、浏览量、发布时间、点赞数、评论数等。
时间跨度为2017年11月14日至2018年6月14日。涵盖了美国、英国、德国、加拿大、法国等国家和地区,每个地区一个文件,考虑到excel所能处理的数据量,本文仅选取了美国的数据进行分析。
“Trending List”的YouTube官方中译是“时下流行”,可以理解为热门视频榜单。类似微博的热搜机制,榜单内容在同一地区是相同的,不根据用户个人的喜好而做个性化推荐。但Trending List并不仅根据播放量等单一指标排序,而是综合了多种因素衡量用户对视频的互动热度(包括播放量、分享数、评论和点赞等)。
1.2 数据来源
通过Google数据搜索引擎,在Kaggle上获取:
1.3 数据内容
数据集为csv格式,文件大小59.85M。数据共计16个字段,40949条。具体字段如下:


更详细的数据集及YouTube介绍参见我的前一篇文章:
Part 2. 提出问题
2.1 视频运营常见指标
有了数据集后,我们可以根据数据集字段,结合行业常用指标提出感兴趣的问题用以分析。
所以在提出具体的问题前,首先需要对视频/短视频运营常见指标有一定的了解。大致可以分为两大类,一类是针对单个视频的指标,另一类则是对视频IP整体的多维度衡量。对具体的指标和含义绘制了思维导图如下:
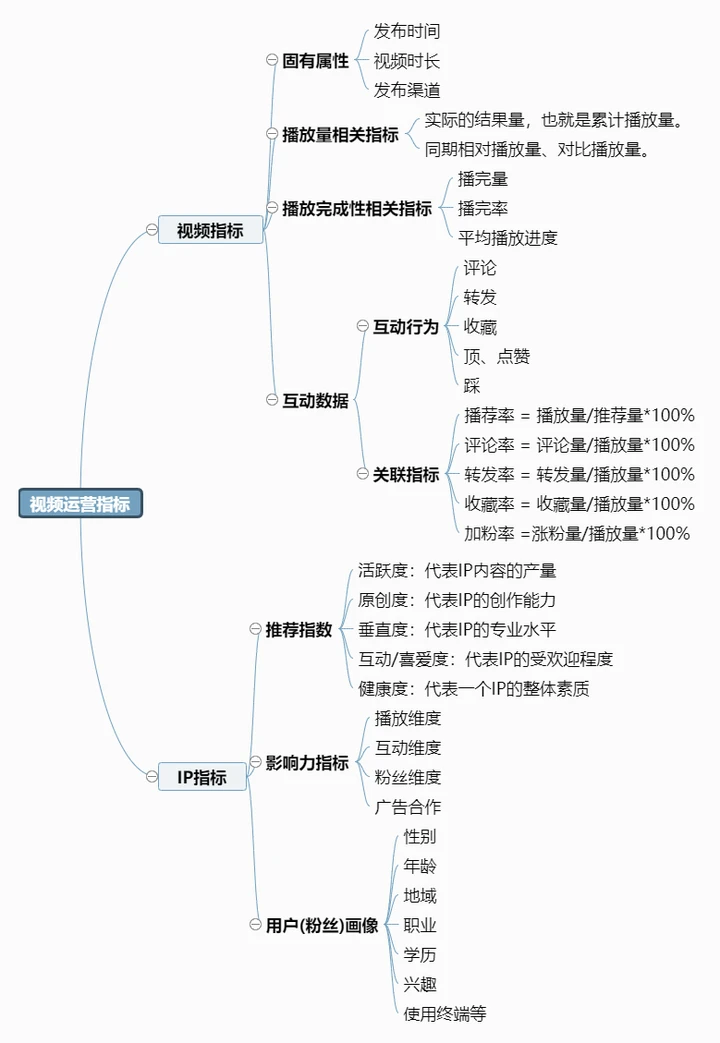
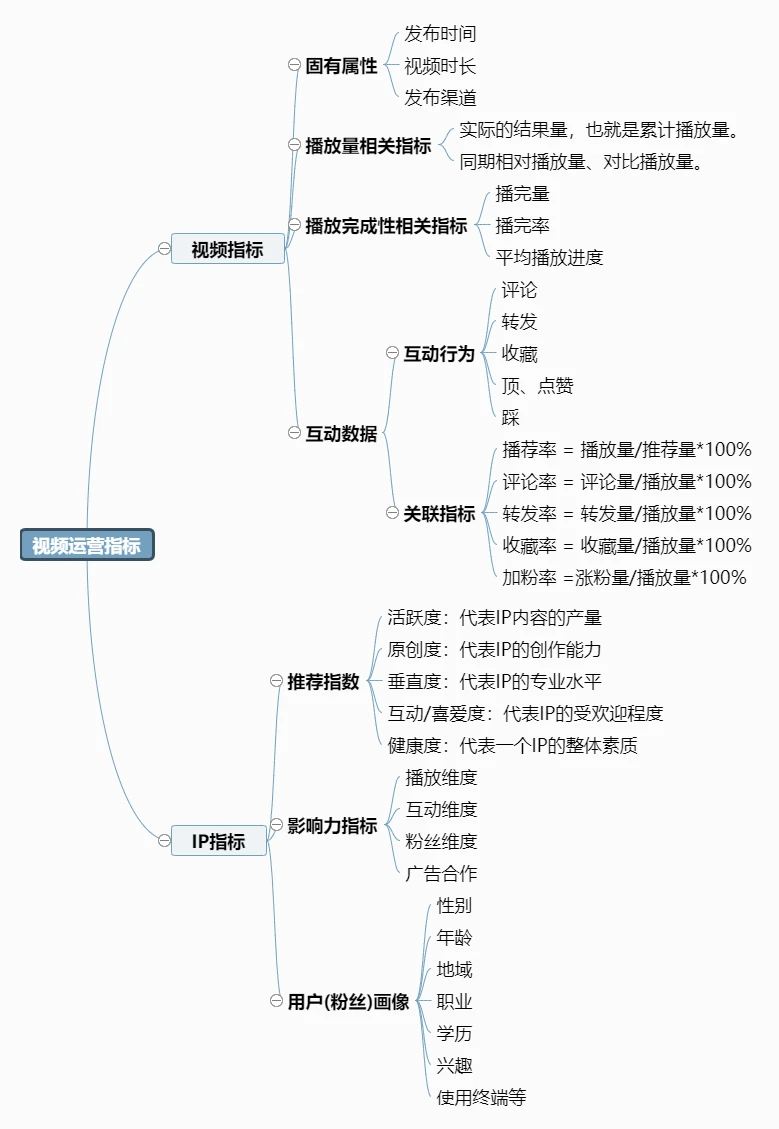
2.2 提出问题
由于本数据集为针对单个视频进行的统计数据,不适用IP指标的相关内容,故根据视频指标部分进行对照如下:
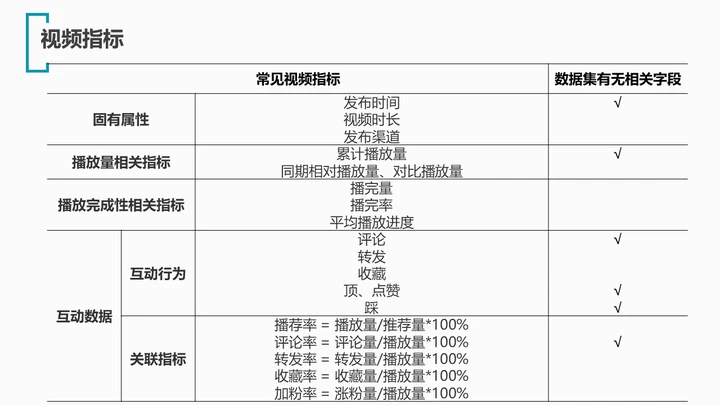
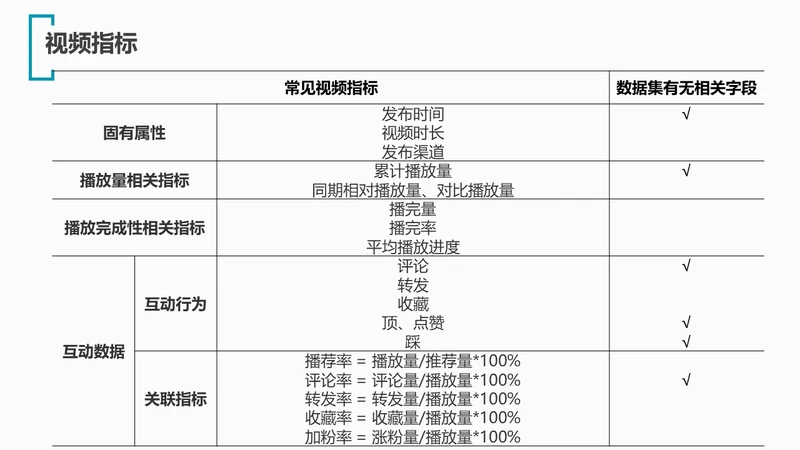
该数据集不含有播放完成性相关的字段;除了上述内容外,数据集在固有属性中还含有视频类别、标签、描述等信息,这些都可以进行分析;且该数据集本身是trending榜单中视频的时间顺序统计,视频可以多次上榜,分析时需要特别注意这一情况。
综上,提出问题如下:


Part 3. 清洗数据
接下来进入正式的数据清洗步骤。数据清洗是一个反复的过程,若增加了新的函数,还需重复检查下是否产生了新的错误值,并针对性地解决。本文数据清洗流程如下:
3.0 编码转换(乱码和数据错位)
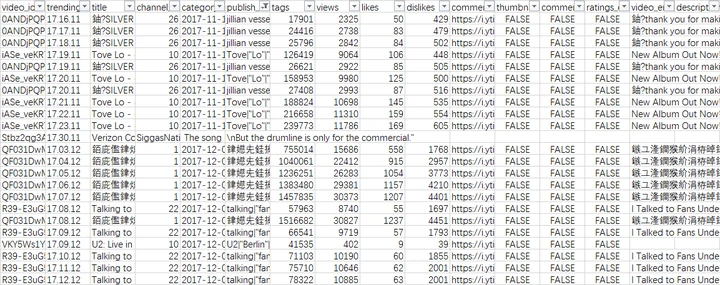
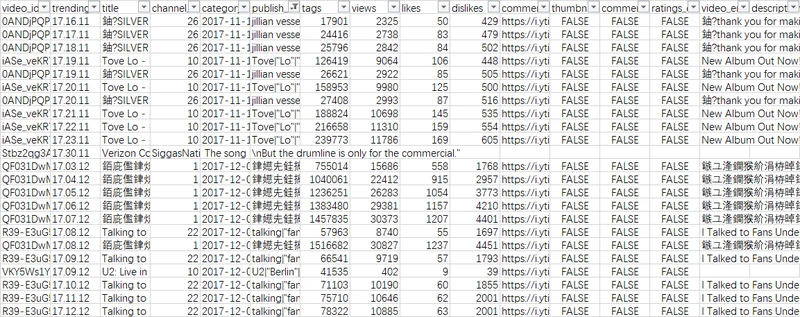
一开始直接使用Excel打开了csv文件,并另存为xls格式。通过筛选功能,发现存在非英文字符的乱码,且注意到有许多错位(值不对位)的情况,如在仅存放布尔值的列,出现数值等,在数值列出现链接等。
解决方式:
将csv文件转为UTF-8-BOM编码(使用notepad++软件等),再用Excel打开存为xls格式,发现错位和乱码问题都得到解决。原因是源数据为ASCII编码,但存在非拉丁字母,需要对编码标准进行转换。
3.1 json文件的转化与整合
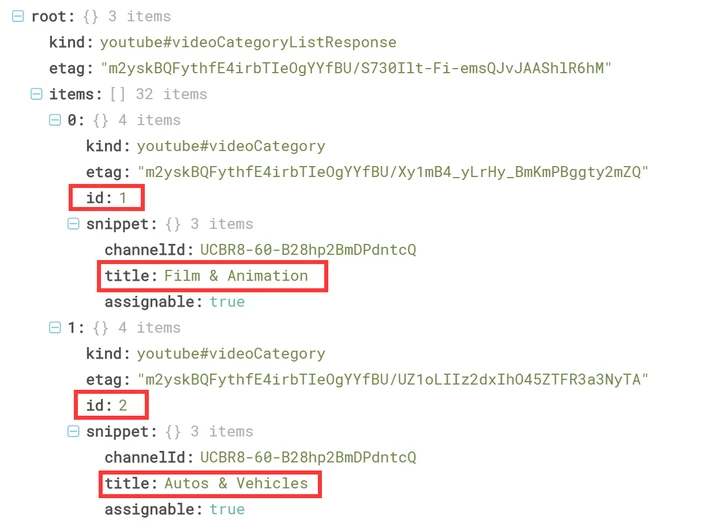
数据中含有视频的category_id(类别编号)但并无其对应的category_title(类别名称)。两者间的对应关系直接采用了原始json格式上传,未整合进主体数据文件中。为了方便进行分析,首先将json文件中的信息提取出来。
该json文件结构如图(仅截取部分),深度不为1,嵌套较多,业务无关字段较多,提取所需字段root-items-id和root-items-snippet-title即可。
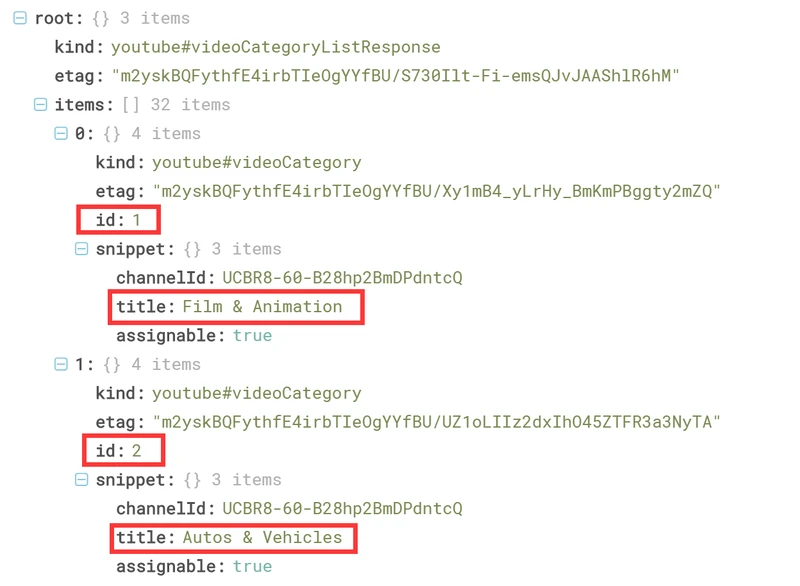
这里采用python进行处理。代码如下:
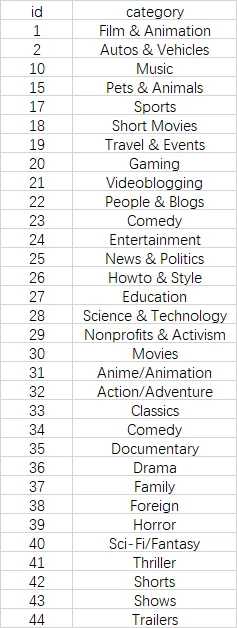
得到的csv文件如图:

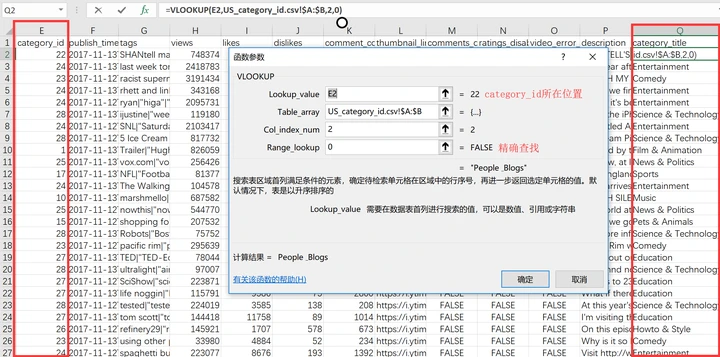
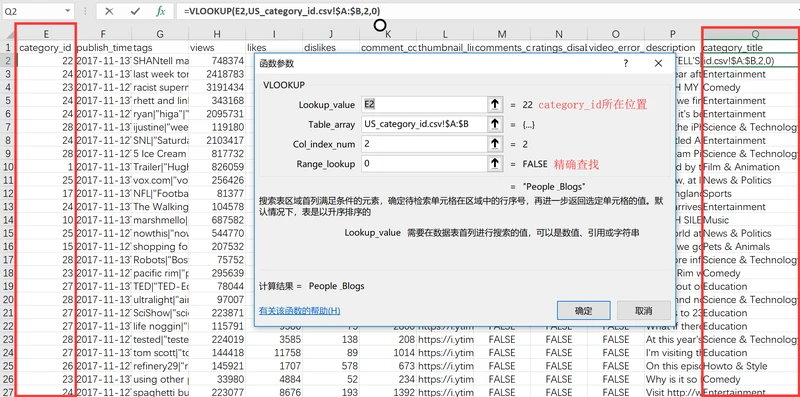
使用vlookup函数将category_title(类别名称)整合进主文件中,如图:
3.2 选择子集
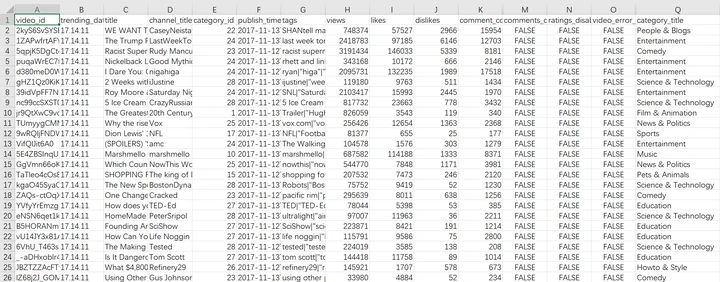
隐藏了与前文所提问题无关的4个字段:
thumbnail_link(缩略图链接)、comments_disabled(是否允许评论)、ratings_disabled(是否允许打分)、video_error_or_removed(视频是否损坏或移除)
3.3 列名重命名
字段命名较规范,能清晰表达数据含义,不再进行重命名。
3.4 删除重复值
重复值是表格中重复的多余数据,常确定一列唯一值(类似SQL中的Unique键),并据此删除重复值。
这里需要注意的是,本数据集中,视频ID的确是唯一确定视频的字段,但Trending榜单存在同一视频多次上榜的情况;而同天的Trending榜单是不变的,若某天内同一视频多次出现则确为重复值。
也就是说我们非但不该直接根据视频ID去重,视频的重复出现反倒是很有挖掘价值的一个方向,但同时也有视频ID唯一的分析需求。
因此,我们在数据清洗的最后,会再将表格分为原版(src.xls)与ID唯一版(id_unique.xls),并根据需要增加一些列。详见后文3.6.5 发布时间与上榜情况。
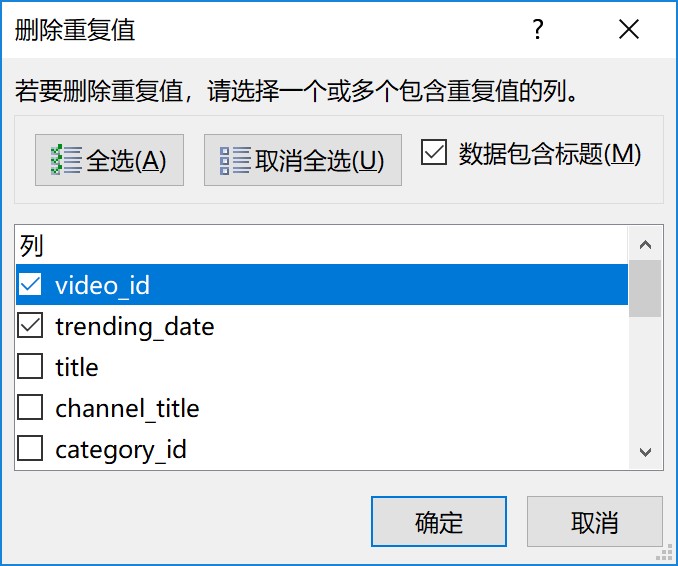
这里仅删去真正的重复值,即对video_id(视频ID)和trending_date(trending日期)两列联合去重,如图:
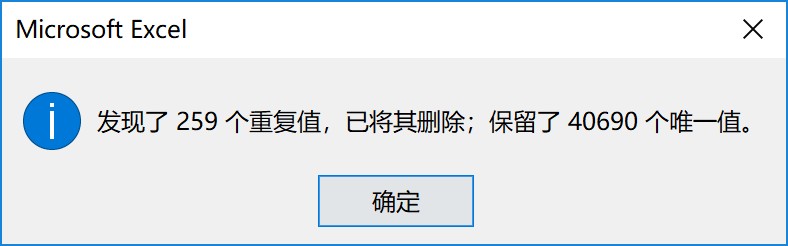
删去了259个重复值,余40690条有效数据:
3.5 缺失值处理
Excel中,选中列可在右下角查看计数。现有40690条数据,各列计数均相符,本数据无缺失值。
3.6 一致化处理
接下来对数据进行一致化处理,对不利于分析的数据类型进行转换,将信息量大的数据拆分,或根据分析需求增加一些字段。
3.6.1 标签计数(tags_num)
tags这一列,多个标签以“|”符号分隔并列,且除了每行首个标签,其余皆带有双引号,例如:Robots|"Boston Dynamics"|"SpotMini"|"Legged Locomotion"|"Dynamic robot"
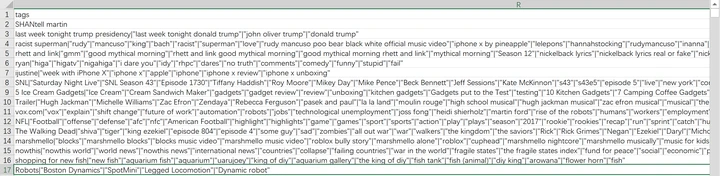
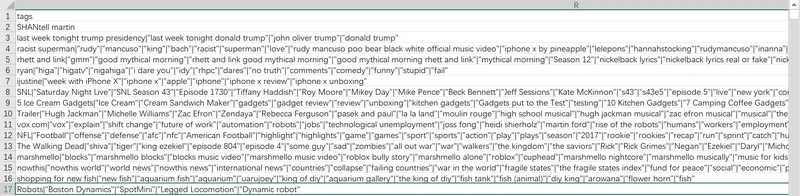
要统计tags的个数,可以等价为统计同一单元格中“|”出现的次数再加上1。
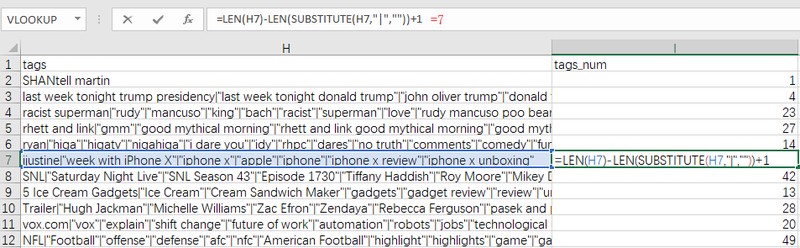
如上图,新增列“tags_num”,输入函数=LEN(H2)-LEN(SUBSTITUTE(H2,"|",""))+1
通过函数substitute()将“|”替换为空,利用字符长度在替换前后的变化,求得被替换字符在单元格中出现的个数。
也可以对“|”符号进行分列,并对分出来的列使用counta()函数统计非空单元格个数,从而达到统计标签个数的目的。
3.6.2 描述长度(description_len)
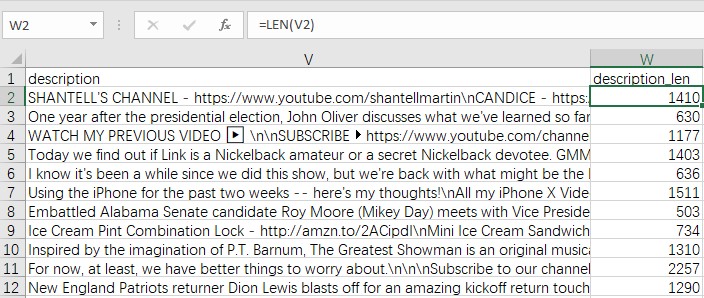
如下图,新增列“description_len”,可以直接使用函数len()统计description(描述)的字符长度:
3.6.3 上榜日期(trending_date)格式的转换
上榜日期trending_data的日期是字符串格式,且采用了欧美习惯的yy/dd/mm(年/日/月)格式,需将其转换为符合我们习惯的日期格式。
使用left()函数取出两位年份,并用"&"连接符在前面补上"20",使年份完整;用right()、mid()函数分别取出月份和日期,再用"&"将"/"符号连在年月日中:
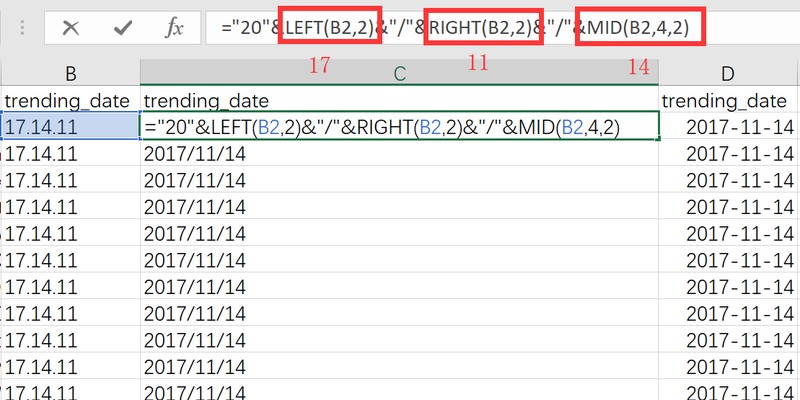
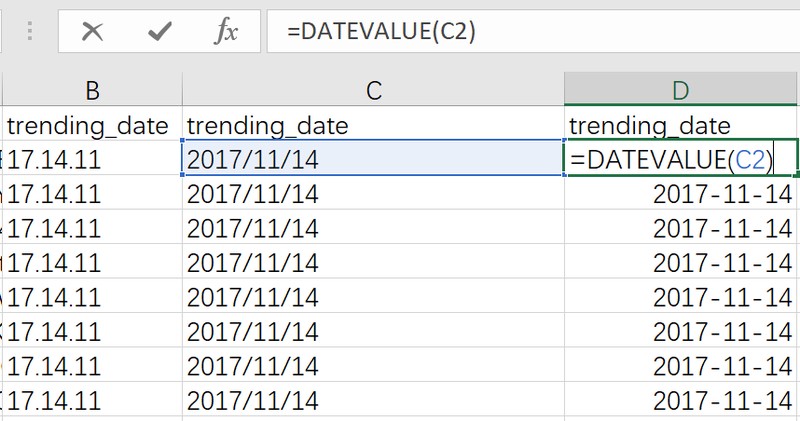
为了excel能正确识别日期,再用datevalue()函数,对前面得到的结果进行进一步处理:
3.6.4 发布时间(publish_time)拆分日期和时间
publish_time同时包含日期和时间,例如: 2017-11-13T17:13:01.000Z
将其分为publish_date和publish_time,便于处理。
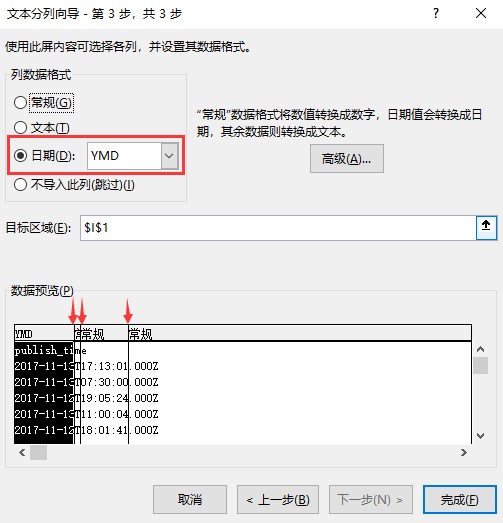
该字段位数固定,可以采用分列进行操作,直接对固定位置分列,或对分隔符"T"和"."进行分列皆可:
或者用类似3.6.3中的方式,使用函数find()配合left()、mid()处理也可以。
同样为使excel能正确识别日期和时间,分别再使用datevalue()和timevalue()函数,进行进一步处理,此处不再赘述。
3.6.5 发布时间与上榜情况
前文3.4 删除重复值一段中已经说过,同一视频可能多次登上trending榜单,根据分析的不同需求,我们最好同时保留原版(src.xls)与ID唯一版(id_unique.xls),并给id_unique.xls增加一些列。
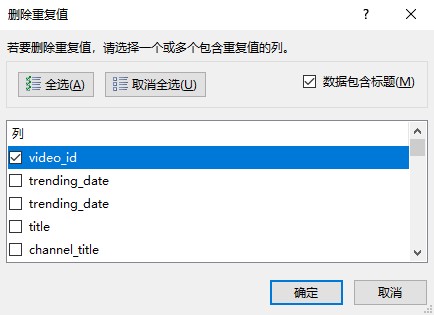
首先对原版(src.xls)的视频ID进行重复值的删除,得到ID唯一版(id_unique.xls),删去了34409条重复数据,保留6281条。
那么,我们究竟需要哪些新列呢?
首先,我们很自然地产生出新的疑问:trending推荐对同一视频来说是连续的么?
要回答这个问题,需要知道视频的首次/末次上榜日期(first/last_trending_date),并计算出差值,得到首末次上榜日期间隔(trending_gap),与视频ID计次得到的上榜次数(trending_times)进行对比,对比需要新增一辅助列(judgement),若一致则说明trending推荐对同一视频来说是连续,若存在不一致则反之。
此外,为了探究发布日期(publish_date)与首次上榜日期(first_trending_date)之间的关系,我们再构造一列pulish_trending_gap,用来指代两者的时间间隔。
综上,我们需要首次/末次上榜日期(first/last_trending_date)、首末次上榜日期间隔(trending_gap)、上榜次数(trending_times)、辅助列(judgement)、发布-首次上榜日期间隔(pulish_trending_gap)六个新列。
首次/末次上榜日期(first/last_trending_date)
在excel2016里,删除重复值时,只保留第一个值。
利用这个特性,我们将视频id和上榜日期(trending_date)两列复制到新的工作表中,对trending_date进行升序排列,对日期来说就是从旧到新;再勾选视频id删除重复值,仅保留了每个视频最旧的上榜日期,即first_trending_date。再使用vlookup函数整合到id_unique.xls中。
Last_trending_date仅在对trending_date排列时使用降序,其他为完全相同的操作。
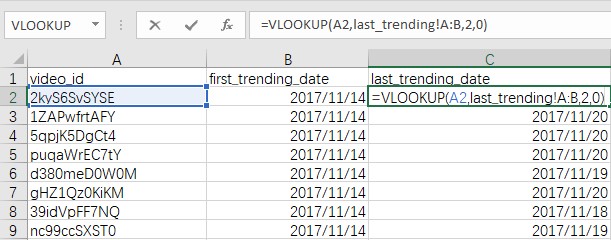
首末次上榜日期间隔(trending_gap)
直接将last_trending_date减去first_trending_date再加1即可,单元格格式为常规。
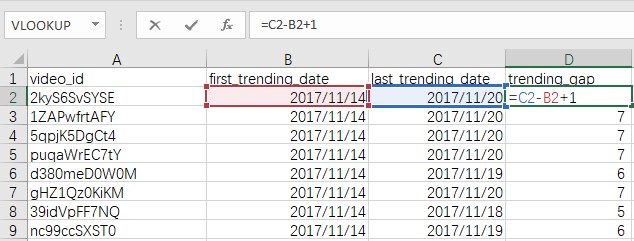
发布-首次上榜日期间隔(pulish_trending_gap)
直接将first_trending_date减去publish_date再加1即可,单元格格式为常规。
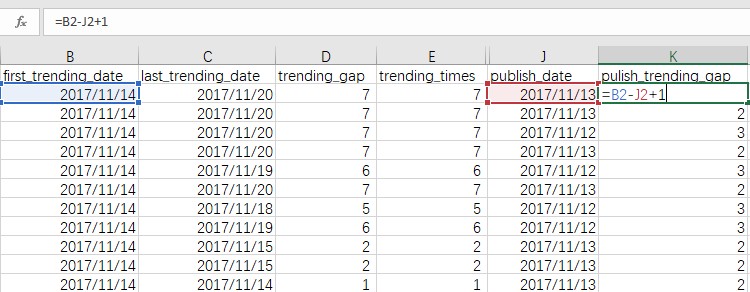
上榜次数(trending_times)
在原版数据(src.xls)中采用函数countif()统计视频id的出现次数,再使用函数vlookup()整合进id_unique.xls中。

辅助列(judgement)
使用if函数,将两个单元格的值相等写成if的条件语句,进行判断:
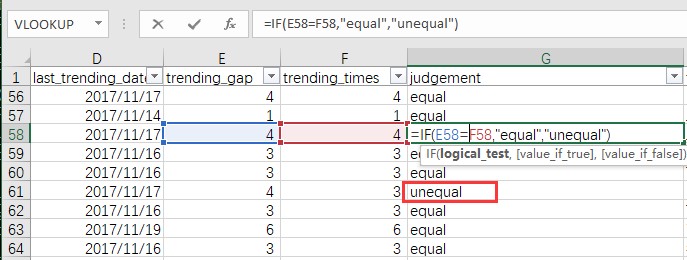
筛选发现有534条不等,现在我们可以回答本节初提出的问题了,trending推荐对同一视频来说并非一定是连续的,但连续的情况确实占了大多数。
Part 4. 分析与可视化
为了让分析部分尽量简洁,后文不再对具体的excel操作进行详述。
主要用到了数据透视表、图表、数据分析功能。
数据透视表功能:插入-数据透视表。插入数据透视表时会包含隐藏的列/行/单元格,若只想对可见单元格进行分析,可以按“Alt”+“;”键选中可见单元格,并复制粘贴到新表再插入数据透视表。
图表功能:选中需要的数据,插入-图表-所有图标。选择需要的箱型图、柱状图、散点图、组合图等。
数据分析功能:首次使用需先加载工具库,文件-选项-加载项-excel加载项-转到分析工具库。在数据-分析-数据分析中调用。本文只使用了其中的相关系数计算。
4.1 Views/likes/dislikes/comment_count的相关系数与指标构建
4.1.1 相关系数
通过excel的“数据分析”功能,对views、likes、dislikes、comment_count四个字段计算相关系数,并利用图表功能绘制散点图,这里需要使用的是视频id唯一的数据文件id_unique.xls。
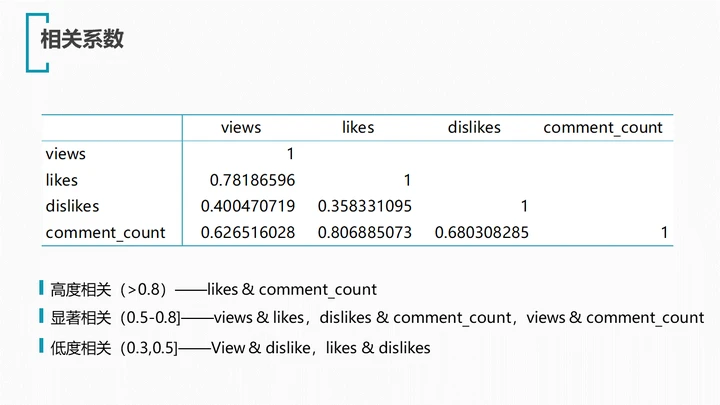
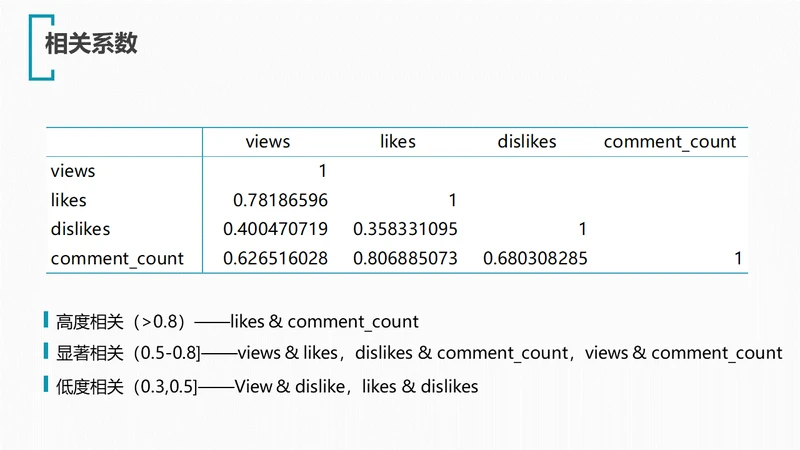
可以看出,点赞数likes与评论数comment_count有着最高的正相关性(r=0.81),紧随其后的是点赞数likes与浏览量views(r=0.78),这是比较符合我们的直觉的,浏览量高的视频受到用户的喜爱,同时用户乐于在喜欢的视频下评论。
有趣的是,不喜欢数dislikes与评论数comment_count同样具有较高的正相关性(r=0.68)。看来令许多人不喜的视频同样能引发广泛的讨论。
4.1.2 指标构建
接下来我们构建些简单的指标,比如likes/dislikes(喜欢/不喜欢)、views/comments(观看数/评论数)。
通过数据透视表对各个类别category的视频分别统计likes和dislikes之和,增加字段likes/dislikes,对该字段降序,并绘制柱状图:
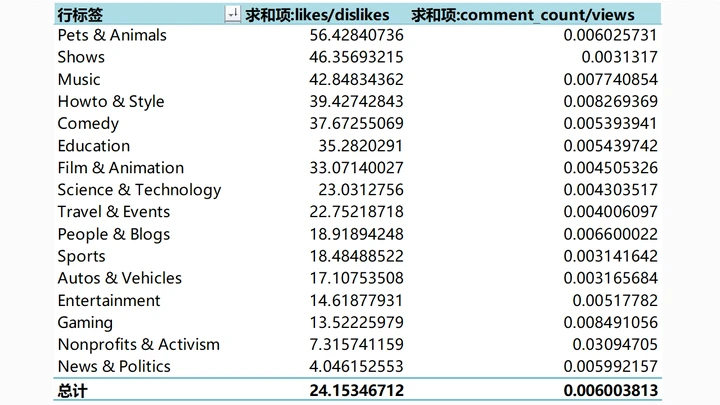
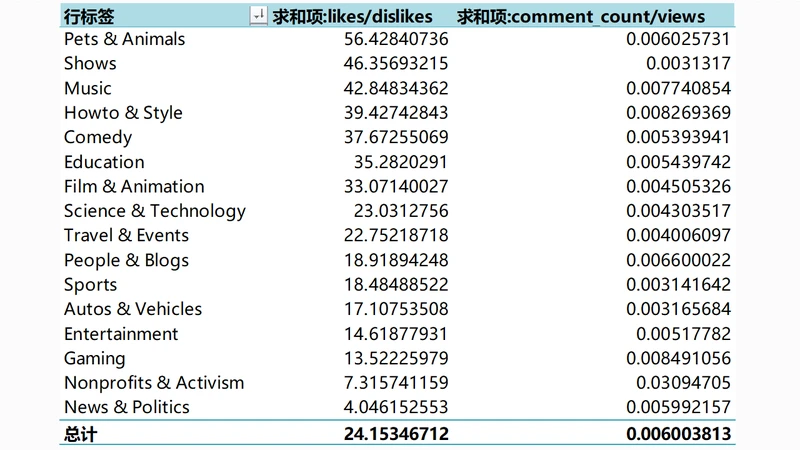
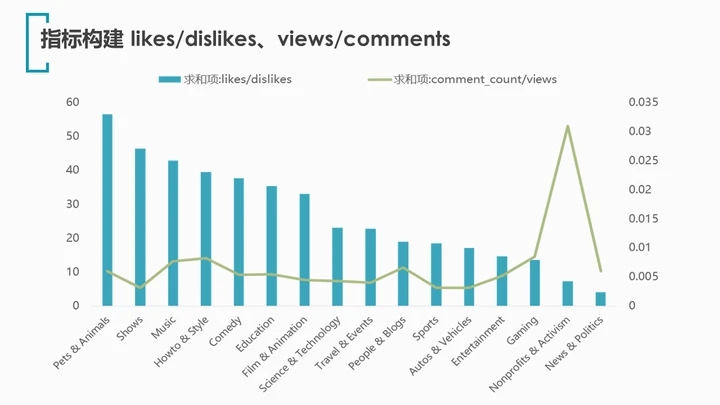
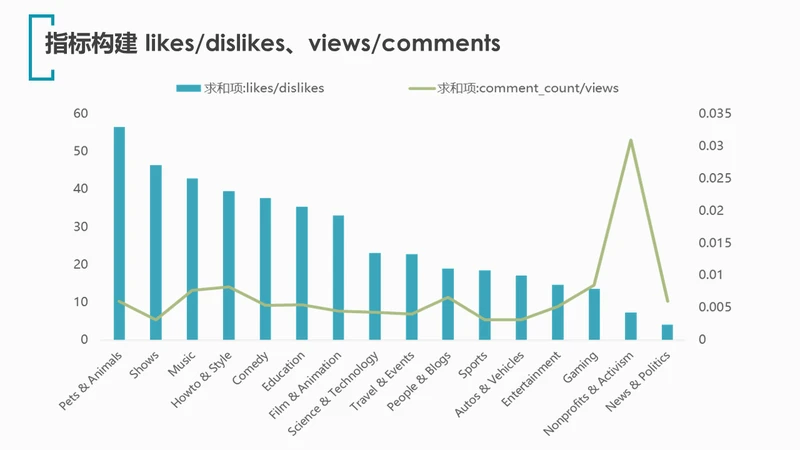
可以看出:
1.类别Pets & Animals(宠物与动物)拥有最高的likes/dislikes比值(56.43),可见宠物着实惹人喜爱,少有人对萌宠题材的视频产生负面情绪。
2.类别News & Politics(新闻与政治)的likes/dislike比值最低,仅为4.05,倒是很符合美国人对政治不满的风格。
3.最特别的当属Nonprofits & Activism(非营利组织与激进主义),likes/dislike比值位居倒数第二,同时comments/views高得出奇,几乎是其他类别的5-6倍。看来此类视频的争议性很大,许多人讨厌该题材,并引发了评论区的诸多争论。
4.2视频的标签数越多越好么?视频描述越详细越好么?
将tags_num与description_len同4.1中的4个字段计算相关系数。

可以看到除了tags_num与description_len两者之间有低度相关外,与其他4个字段的相关系数绝对值都小于0.05,不存在线性相关。
看来标签数量和描述长度与视频的浏览量、点赞数、评论数之间并无什么关系。
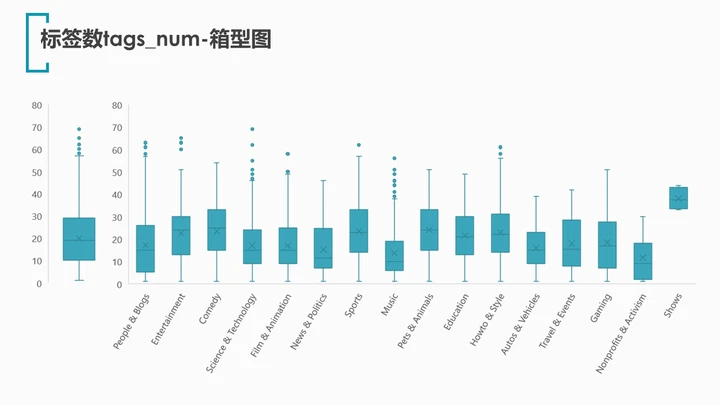
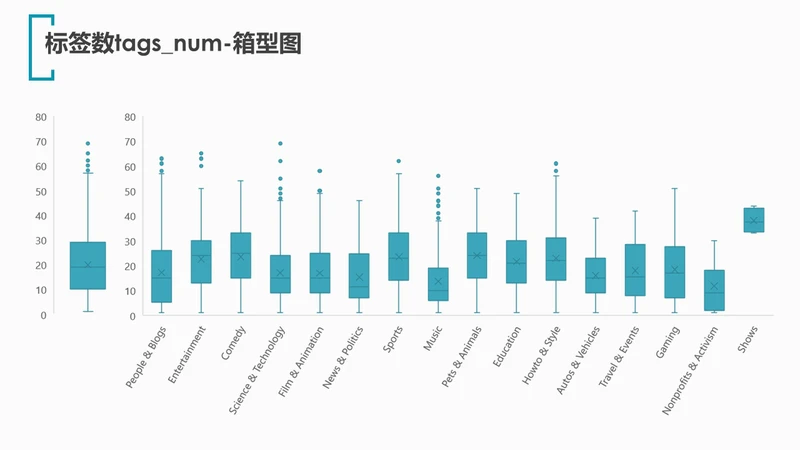
对于标签数tags_num绘制箱型图,可以看出trending视频的标签数集中在19-29个之间;再分类别绘制箱型图,发现shows类别的上传者最喜欢打标签:
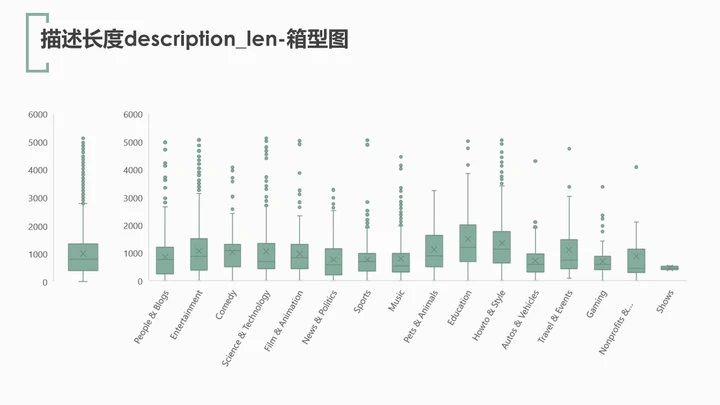
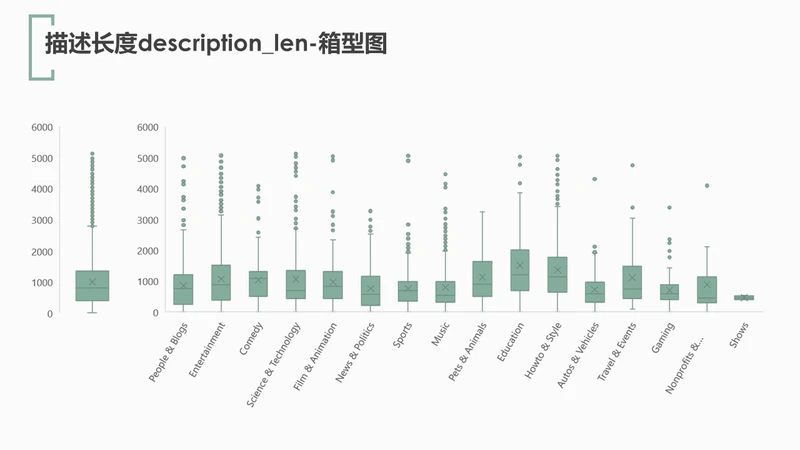
对视频描述长度description_len绘制箱型,可知字符长度集中在388-1348之间。同样对其分类别绘制箱型图,其中education(教育类)和how to & style(教程类)视频的上传者在写描述时里最为“话痨”。(嗯,这看起来和教育者以及教程类的特性还是很相符的嘛…
4.3 什么类别登上trending榜单的次数/视频数量最多?
对类别和trending_times求和项、video_id计数项拉取数据透视表,并绘制柱状/折线组合图。

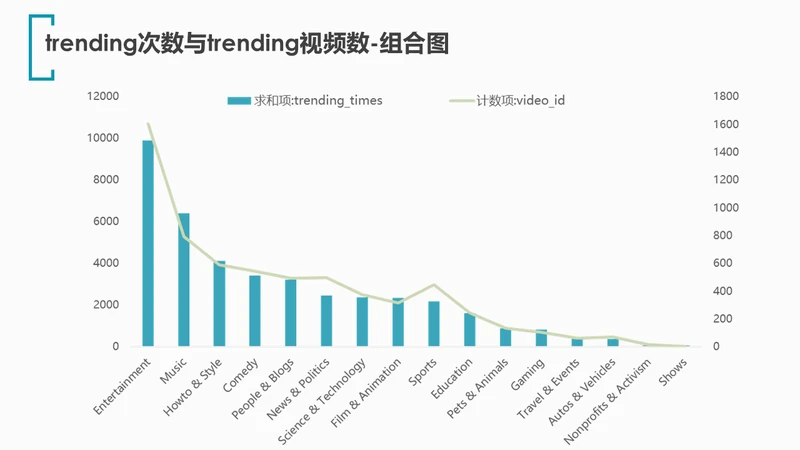
1.无论从视频数量还是上榜次数来看,entertainment娱乐类都占据了trending榜单的第一,甩开了其他类别一大截。娱乐类是大众接受度最高,同时也是热度最高的类别。
2.整体趋势上看 trending次数与trending的视频数量有很强的正相关关系。
3.此外注意到,其实有很多类别完全没有登上过trending榜单。
4.4 Trending榜单上的视频通常能上榜多少次?
对trending_times绘制箱型图。
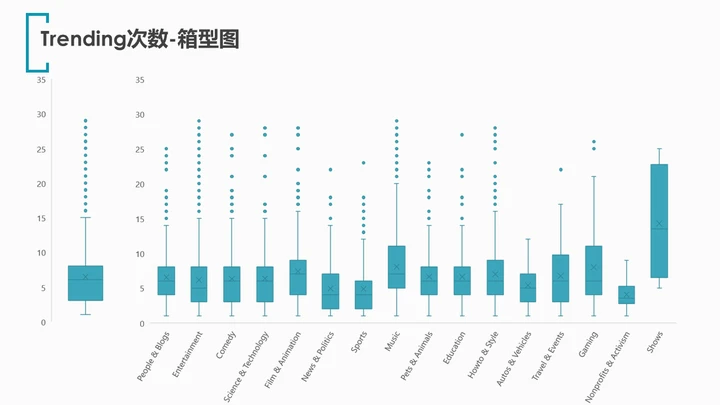
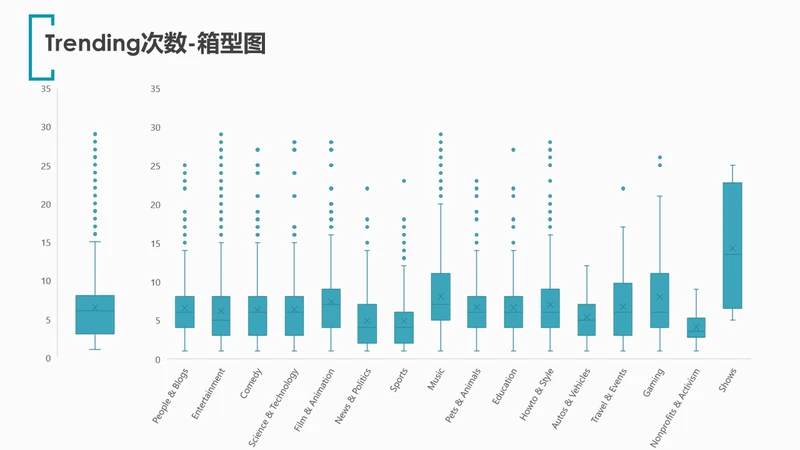
无论是总体来看还是分类别查看,绝大多数视频的上榜次数都集中在3-8次。
但同时也存在不少离群点,说明仍有一定数量的视频能反复十余次甚至二十余次上榜。
类别shows,结合前文来看,虽然只有4支视频登上trending榜单,但上榜的平均次数反倒是最多的。
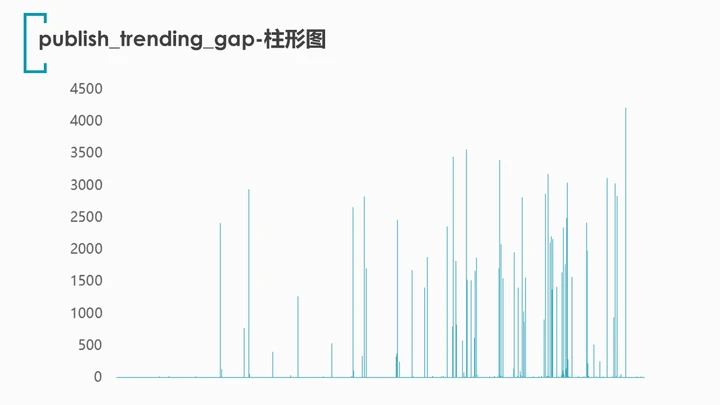
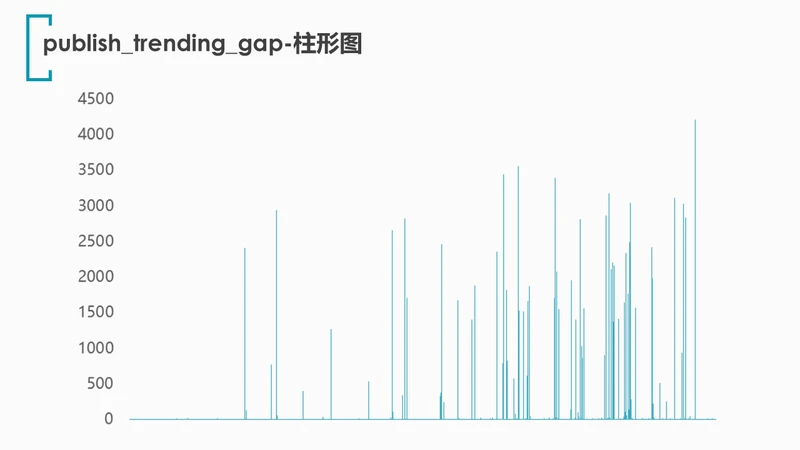
4.5 视频的发布日期与首次上榜(trending)日期之间是否存在某种关系?
首先让我们来看看发布-上榜时间间隔(publish_trending_gap)的柱形图:
为了探究上榜次数(trending_times)与发布-上榜时间间隔(publish_trending_gap)之间的关系,再绘制散点图:
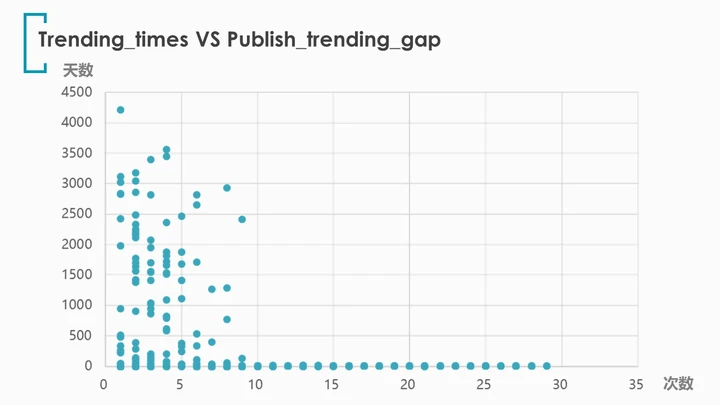
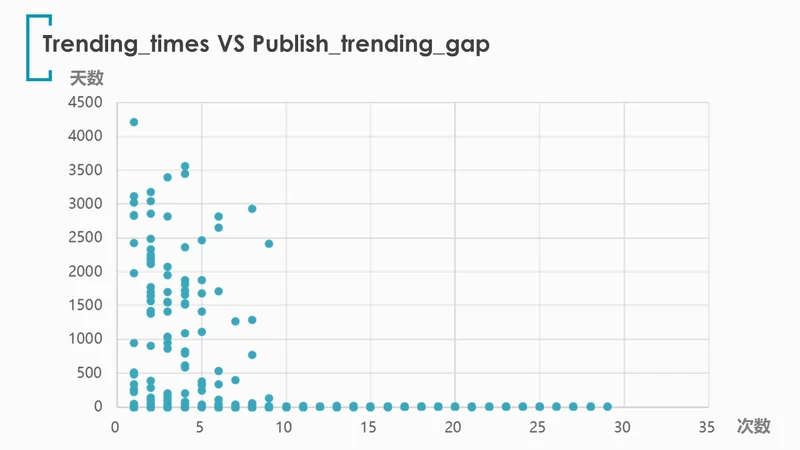
非常有趣,我们发现了居然有4215天(近12年)后才首次登上trending榜单的视频,并且此类“大器晚成”的视频并不算罕见,365天以上才被推荐的共有69个。
同样有趣的是上榜12次以上的视频无一例外都是在2天内就首次上榜的。看来爆款视频从出生起就闪耀着爆款的光芒。
4.6 是否存在视频发布的黄金时间(每周/每天中是否存在周期性的高热度)?
4.6.1 周(week)
对发布时间publish_date使用weekday()函数,参数return_type选择2(周一作为每周的第一天),得到代表星期的对应数值,星期一为1,星期二为2,以此类推。
插入数据透视表,对trending_times的总和值和视频个数,绘制柱形-折线组合图:
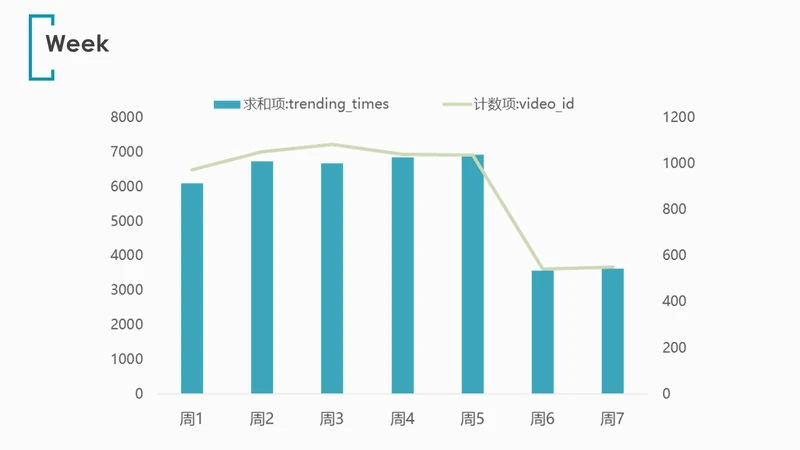
发现周末发布的视频反而在trending榜单上居于劣势,无论从视频数量还是次数来说都是如此。而周一到周五发布的视频,表现明显优于周末,且较为平均。这与我们“周末会有更多人有空看视频”的直觉相违背,猜测可能是由于职业的视频发布者遵循周末休息的习惯,或是YouTube推荐机制的内因。
4.6.2 小时(hour)
拉取数据透视表,对publish_time同时绘制trending_times和视频数量的折线图:
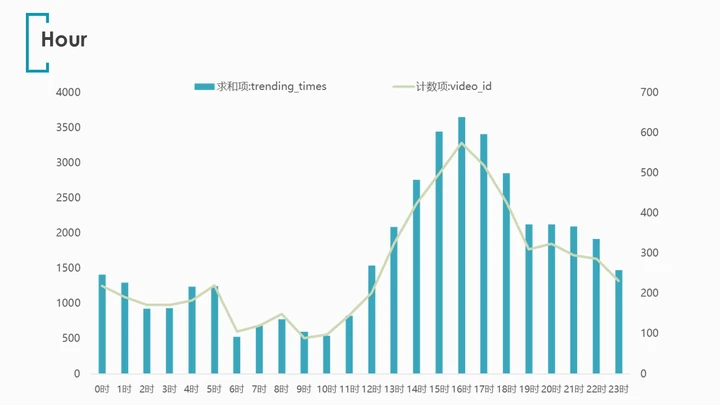
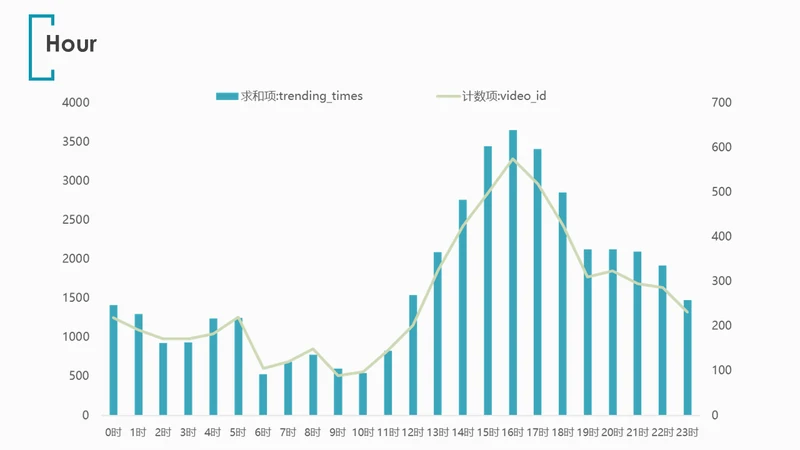
发现trending榜单中14时-18时发布的视频占了绝大多数,特别是16时前后更是达到了顶峰,晚间发布的视频也较多,凌晨1点后至上午12时前进入视频发布的低谷期。
但这里缺少YouTube总体视频的发布时间进行对比,不能断言究竟是16时本就是视频发布高峰期,使得trending榜单呈现类似的分布,抑或这真的是一个黄金的视频发布时间。
但不论如何,可以肯定的是16时都是一个很值得注意的视频发布时间。
Part 5. 总结




如有任何数据分析相关问题,欢迎大家在评论里提问,很乐意和大家探讨。

