

引言
使用一些建模分析手段来评价电影的成功已经屡见不鲜,这类预测模型常常使用注入电影制作成本,类型,主演,出品方等结构化数据作为输入。然而,在社交媒体日益发达的现在,人们时常会在Twitter,Facebook等网站上发表自己的意见和建议。社交媒体已然是衡量电影观众情绪的潜在工具了。
本文将以2017年的宝莱坞电影“Rangoon”为例子,用R语言来分析Twitter用户对他的情感评价。
目录
- 文本挖掘导论
- 分析目标
- 数据
- 分析过程1 使用“tm”包
- 分析过程2 使用“suazyhet”包
- 结论
- 为电影预测构建一个算法
1. 文本挖掘导论
在进入正题之前,我们不妨问这样一个问题:什么是文本挖掘?
简而言之,文本挖掘就是把非结构化的文本数据转化为有意义的观点的过程。转化后的观点可以针对用户建议,产品评价,情感分析和消费者反馈等
与传统方法依靠的结构化数据不同,文本挖掘的对象是结构松散有诸多语法和拼写错误的文本,而且还时常包含多种语言。这使得整个挖掘过程变得更有趣且富有挑战性。
在文本挖掘领域有两大常用方法:情感分析和词包挖掘(Bag of Words,a.k.a bow model)。
情感分析关心单词的结构和语法,词包挖掘则是把文本(句子,微博,文档)视作单词的集合(包)。
2. 分析目标
每个分析项目都应该有个明确的目标,本文的目标就是对Twitter数据使用文本挖掘技术来获取用户对电影“Rangoon”的情感评价。
3. 数据
分析的第一步就是要获取数据,如今获取Twitter数据只需要通过网页爬虫或者API就可以实现。本文则使用R语言中的“twitterR”包收集了10000条关于“Rangoon”的推文
我使用了“twitterR”采集了10000条关于“Rangoon”的推特和回复,这部电影与2017年2月24日上映,我采集了2月25日的推特并把它们存在csv文件里,再用“readr”包读入R里。从推特采集数据的过程超出了本文的范畴,暂且不表。
- # 加载数据
- library(readr)
- rangoon = read_csv("rangoontweets.csv")
4. 用“tm”包进行分析
“tm”包是在R内进行文本挖掘的框架,它会基于广泛使用的“Bag of Words”原则进行分析。这一方法非常简单易用,它会统计文本中每个词的频率,然后把词频作为变量。这一看似简单的方法其实非常有效,并且现在已经成了自然语言处理领域的基准。
主要步骤如下:
Step 1: 加载相应的包并且提出数据
- # 加载包
- library('stringr')
- library('readr')
- library('wordcloud')
- library('tm')
- library('SnowballC')
- library('RWeka')
- library('RSentiment')
- library(DT)
- # 提出相关数据
- r1 = as.character(rangoon$text)
Step 2: 数据预处理
对文本进行预处理可以显著提升Bag of Words方法(其他方法也是)的效果。
预处理的第一步是构建语料库,简单地说就是一本词典。语料库一旦建立好了,预处理也就完成了大半。
首先,让我们移除标点,基础方法就是把不是数字和字母的对象移除。当然,有时标点符号也很有用,像web地址中标点就有提示符的作用。所以,移除标点要具体问题具体分析,本文中则不需要它们。
之后,我们把单词都变成小写防止统计错误。
预处理的另一个任务是把没有用的词组去掉,很多词被频繁使用但只在句子里才有意义。这些词被称为“stop words”(停词)。举个例子,像the,is这些词就是停词,它们对之后的情感分析无甚作用,所以就把它们去掉来给数据瘦身。
另一个重要环节是stemming(词干提取),他能把不同结尾的词转换成原始形式。比如,love,loved,loving这些词之间的差异很小,可以用一个词干也就是lov来代表它们,这个降维过程就叫词干提取。
一旦我们把数据预处理好了,我们就可以开始统计词频来为未来建模做准备了。tm包提供了一个叫“DocumentTermMatrix”的来完成相应功能,它会返回一个矩阵,矩阵的每一行代表文档(本例中是一条推特),列就代表了推特中的单词。具体的数据就代表了每条对特相应单词的出现频率。
我们生成这个举证并把它命名为“dtm_up”。
- # 数据预处理
- set.seed(100)
- sample = sample(r1, (length(r1)))
- corpus = Corpus(VectorSource(list(sample)))
- corpus = tm_map(corpus, removePunctuation)
- corpus = tm_map(corpus, content_transformer(tolower))
- corpus = tm_map(corpus, removeNumbers)
- corpus = tm_map(corpus, stripWhitespace)
- corpus = tm_map(corpus, removeWords, stopwords('english'))
- corpus = tm_map(corpus, stemDocument)
- dtm_up = DocumentTermMatrix(VCorpus(VectorSource(corpus[[1]]$content)))
- freq_up <- colSums(as.matrix(dtm_up))
Step 3: 计量情感
现在是时候来进行情感打分了。R中的“calculate_sentiment”函数可以完成这一工作,它会读入文本并计量每个句子的情感得分。这一函数会把文本作为输入,输出一个包含每个句子情感得分的向量。
让我们来实现这一功能。
- # 计量情感
- sentiments_up = calculate_sentiment(names(freq_up))
- sentiments_up = cbind(sentiments_up, as.data.frame(freq_up))
- sent_pos_up = sentiments_up[sentiments_up$sentiment == 'Positive',]
- sent_neg_up = sentiments_up[sentiments_up$sentiment == 'Negative',]
- cat("We have far lower negative Sentiments: ",sum(sent_neg_up$freq_up)," than positive: ",sum(sent_pos_up$freq_up))
我们发现褒义词和贬义词的比例是5780/3238 = 1.8,乍一看电影还是受到观众的好评的
让我们分别深入挖掘好拼和差评来获取更深的理解。
– 褒义词
下方的表格展示了被分类为好拼的文本的词频,我们通过datatable函数实现这个功能。
“love”,“best”和“brilliant”是好评中的三大高频词。
- DT::datatable(sent_pos_up)
- textsentimentfreq_upaccomplishaccomplishPositive1adaptadaptPositive2appealappealPositive4astonishastonishPositive3awardawardPositive85aweawePositive11awestruckawestruckPositive5benefitbenefitPositive1bestbestPositive580betterbetterPositive186
我们可以把这个结果用词云进行可视化,词云中单词个头越大代表它出现频率越高。
– 褒义词词云
- layout(matrix(c(1, 2), nrow=2), heights=c(1, 4))
- par(mar=rep(0, 4))
- plot.new()
- set.seed(100)
- wordcloud(sent_pos_up$text,sent_pos_up$freq,min.freq=10,colors=brewer.pal(6,"Dark2"))
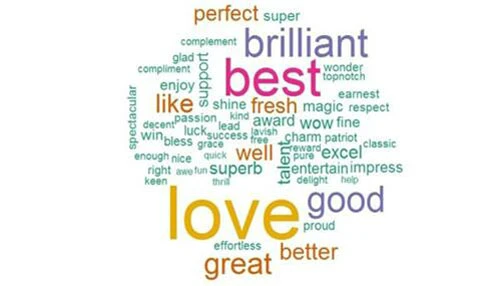
词云也显示了love是好评中频率最高的单词。
– 贬义词
重复之前的步骤,贬义词中“miss”,“dismal”和“hell”是top3,让我们也用词云来可视化。
- DT::datatable(sent_neg_up)
- textsentimentfreq_upabruptabruptNegative3addictaddictNegative1annoyannoyNegative3arduousarduousNegative1attackattackNegative2awkwardawkwardNegative2badbadNegative64badbadNegative64baselessbaselessNegative1bashbashNegative5beatbeatNegative22
贬义词词云
- plot.new()
- set.seed(100)
- wordcloud(sent_neg_up$text,sent_neg_up$freq, min.freq=10,colors=brewer.pal(6, "Dark2")

注意:在文本分析时,最好对分析的对象有一定了解。比如“bloody”或者“hell”这样的贬义词可能是从电影的插曲“bloody hell”中被统计出来的。相似的,“miss”也可能来自于Ragoon中的女性人物“Miss Julia”,这样把它作为贬义词处理可能就不合适了。
考虑到这些异象,我们要对分析结果做进一步处理。之前统计的褒贬词的比例是1.8,现在3238个贬义词中的144个“hell”先不考虑,这样这个比例会上升到1.87。
这是得到观众对Rangoon平价的第一步,看起来好评居多,我们需要用更细致的方法省查这一结论。
5. 用 “syuzhet” 包进行分析
“syuzhet”包会使用3个情感词典来进行情感分析。与上述方法不同,它能分析更广范围的情感。当然,第一步还是要对数据进行预处理,包括对html链接进行清洗。
- # 方法2 - 使用syuzhet包
- text = as.character(rangoon$text)
- ## 去掉回复
- some_txt<-gsub("(RT|via)((?:\\b\\w*@\\w+)+)","",text)
- ## 清洗html链接
- some_txt<-gsub("http[^[:blank:]]+","",some_txt)
- ## 去掉人名
- some_txt<-gsub("@\\w+","",some_txt)
- ## 去掉标点
- some_txt<-gsub("[[:punct:]]"," ",some_txt)
- ## 去掉数字
- some_txt<-gsub("[^[:alnum:]]"," ",some_txt)
这个函数会输出一个数据框,每一行代表原始文件的一个句子,每一列代表一种情感类型和正负情感配比。一共有十列,代表“anger”, “anticipation”, “disgust”, “fear”, “joy”, “sadness”, “surprise”, “trust”, “negative”, “positive”。
让我们把这个结果也可视化
- # 可视化
- library(ggplot2)
- library(syuzhet)
- mysentiment<-get_nrc_sentiment((some_txt))
- # 得到每种情感的得分
- mysentiment.positive =sum(mysentiment$positive)
- mysentiment.anger =sum(mysentiment$anger)
- mysentiment.anticipation =sum(mysentiment$anticipation)
- mysentiment.disgust =sum(mysentiment$disgust)
- mysentiment.fear =sum(mysentiment$fear)
- mysentiment.joy =sum(mysentiment$joy)
- mysentiment.sadness =sum(mysentiment$sadness)
- mysentiment.surprise =sum(mysentiment$surprise)
- mysentiment.trust =sum(mysentiment$trust)
- mysentiment.negative =sum(mysentiment$negative)
- # 绘制柱状图
- yAxis <- c(mysentiment.positive,
- + mysentiment.anger,
- + mysentiment.anticipation,
- + mysentiment.disgust,
- + mysentiment.fear,
- + mysentiment.joy,
- + mysentiment.sadness,
- + mysentiment.surprise,
- + mysentiment.trust,
- + mysentiment.negative)
- xAxis <- c("Positive","Anger","Anticipation","Disgust","Fear","Joy","Sadness","Surprise","Trust","Negative")
- colors <- c("green","red","blue","orange","red","green","orange","blue","green","red")
- yRange <- range(0,yAxis) + 1000
- barplot(yAxis, names.arg = xAxis,
- xlab = "Emotional valence", ylab = "Score", main = "Twitter sentiment for Movie Rangoon 2017", sub = "Feb 2017", col = colors, border = "black", ylim = yRange,
- xpd = F, axisnames = T, cex.axis = 0.8, cex.sub = 0.8, col.sub = "blue")
- colSums(mysentiment)
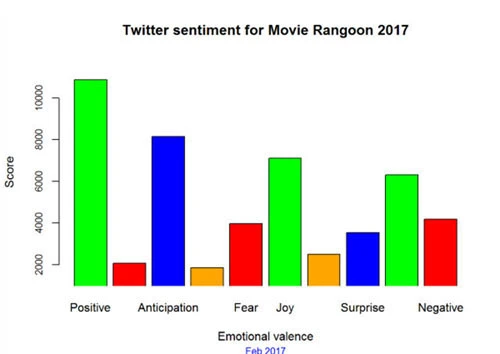
看看这个柱状图和每种情感的总和,积极情感(“positive”,“joy”,“trust”)比消极情感(“negative”,“disgust”,“anger”)得分高很多。这或许暗示了观众对电影评价比较正面。
6. 结论
两个方法都表名电影“Rangoon”得到了观众的肯定。
7. 对电影表现构建一个预测模型
本文专注于对电影“Rangoon”相关推特进行情感分析,然而对于预测票房而言这可能不是很有作用。众所周知,很多电影叫好不叫座,一些脑残片却能赚得盆满钵满。
这可咋整?
解决方案就是分析同类型电影的PT/NT比(好评差评比例)转换为票房的历史数据,并构建一个拟合与预测兼优的模型。这个模型可以用来预测电影是否会获得商业上的成功,在Rangoon这个例子里,1.87会被作为输入的值。
由于这个问题超过了本文的范畴,我们不会展开讨论。但需要注意的是文本分析也能用来预测电影票房。
结语
本文使用电影相关推特来进行情感分析,需要注意的是采集的推特的发表时间可能很重要。在电影上映前后的推特可能在情感上有很大分歧,不同的预处理方式也会影响到结果。
本文的目的不在分析电影Rangoon的好坏,而是提出了情感分析的具体步骤。在这一领域还有很多先进的方法,本文介绍的两个方法是最简单直观的。

