
大家好,我是蘑菇先生。
Twitter近期开源了其推荐系统源码[1,2,3],截止现在已经接近42k star。但网上公开的文章都是blog[1]直译,很拗口,因此特地开个系列系统分享下。系列涵盖:
- Twitter整体推荐系统架构:涵盖图数据挖掘、召回、精排、规则多样性重排、混排等。参见材料[1,2]。
- Twitter精排模型(Heavy Ranker):包含模型结构、特征工程、多目标建模、多目标融合等,看了下居然是出自新浪微博DLP-KDD 2021的工作。参见材料[3]。
- Twitter图模型预训练表征(TwHIN embeddings):基于社交异构图对用户、推文做预训练,Twiiter自研TwHIN KDD 2022的工作。参见材料[3]。
本篇文章先分享Twitter整体的推荐系统架构。
引言
Twitter场景下推荐系统问题定义:
- 输入:Twitter network,由推文、用户、交互行为等构成的超大规模异构图。
- 输出:预测你和推文或其他用户交互的概率,进行推文或用户的推荐。
整体问题和常见的推荐系统差别不大。特色的地方在于Twitter比较关注social graph的挖掘,包括图特征、图预训练、图召回以及图模型等。
整体架构如下图,包括数据、特征工程和推荐系统服务Home Mixer。
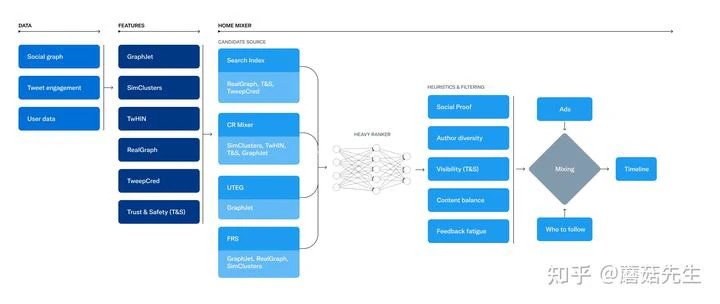
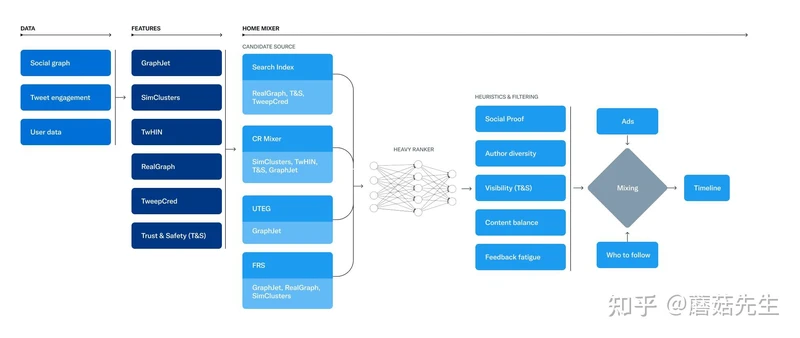
数据:涵盖了社交图、用户的交互行为、用户画像数据等。数据这块是Twitter 的核心资产,由用户、推文和互动构成的超大规模异构社交图。
特征工程:Twitter主要关注社交图的预训练、聚类、社区发现等,这也是Twitter的特色所在。图预训练得到的向量可以用于向量召回、精排特征等。此外,还包括一小部分安全相关的工作。
推荐系统核心服务:Home Mixer,Twitter定制的Scala框架。可以认为是算法工程。类比国内大厂用的Java、Go、C++等。由三大部分构成:
- 召回:Candidate Sources,从不同的推荐源获取最好的推文,类似推荐系统的召回阶段。Candidate Retrival。核心召回路是图召回。
- 粗精排:使用机器学习模型对推文进行打分排序,Twitter分为Light Ranker和Heavy Ranker。分别类比推荐系统的粗排和精排阶段。
- 重排/混排:应用启发式规则,例如过滤来自已屏蔽用户的推文、NSFW内容和已看到的推文;保证作者多样性等;以及负责广告、推文和作者混排等。
下面会围绕召回、粗排、精排、混排展开介绍。特征部分不单独设章节,会在召回和粗排中用到的地方介绍。
召回
Twitter有很多召回数据源,为用户召回最新、最感兴趣的相关推文。
- 输入:推文候选池大小,hundreds of millions 亿万级别。
- 输出:两类召回通道:你关注的用户圈(in-network)、你未关注的用户圈(out-of-network),整体上,二者比例是55开,即召回一半你关注用户的推文、一半你未关注的用户的推文。当然,不同用户召回的配比会不一样。
In-Network召回
主召回路,也是最大的候选推文来源,目标是从你关注的作者推文中,检索出最新、你最可能感兴趣的推文给你,能贡献50%的推文来源。使用自研搜索引擎Earlybird[6],检索你关注的人的推文,本质是个倒排索引。只不过索引里检索到的推文要过一个Light ranker海选粗排模型进行该召回路的截断,放在下文的粗排章节中介绍。
Out-of-Network 召回
在用户关注圈子之外寻找相关的推文推荐给用户。Twitter采取了两类召回方法:
UserTweetEntityGraph (UTEG):协同过滤。通过分析你关注的人或有相似兴趣的人的行为,来预测你感兴趣的相关推文,比如:主要是二跳关系U2U2I,为了实现高效动态图构造和游走,内部自研了GraphJet[5]图引擎,发表在VLDB 2016上。GraphJet能够高效、动态地维护一个实时交互图(real-time interaction graph),结点为用户和推文,边为实时交互行为,并实现高效地图游走。该方法大概能涵盖15%的推文来源。该方法得到的召回结果也要过一个Light Ranker进行海选粗排。
Embedding Spaces:表征学习。建模更加通用的问题:你对哪些推文以及哪些作者感兴趣。表征学习目标是训练得到用户表征向量和推文表征向量,再通过计算user-user、user-tweet表征之间的相似性来预测用户兴趣。主要分为稀疏嵌入和稠密嵌入两种,前者通过聚类来做表征、后者基于图学习做预训练。
- 稀疏嵌入:最有用的表征模型是SimClusters[7],发表在KDD 2020上,基于社区发现的异构表征模型,利用矩阵分解算法,基于social graph中有影响力的用户进行社区发现,并根据流行度和用户行为将推文和用户划分到不同空间中。一共有14.5W个社区,每3周更新一次,社区有的很大,有的很小,一个用户可以属于多个社区;每个推文也可以用社区来做嵌入,用推文在每个社区的流行度作为表征值。社区形如:
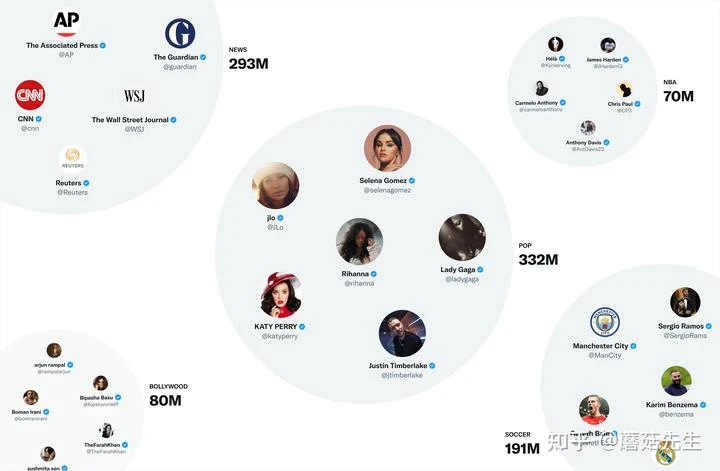
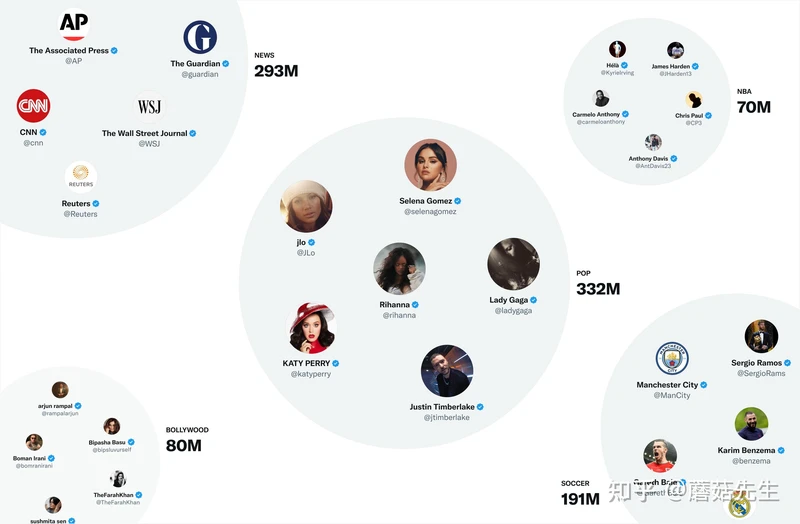
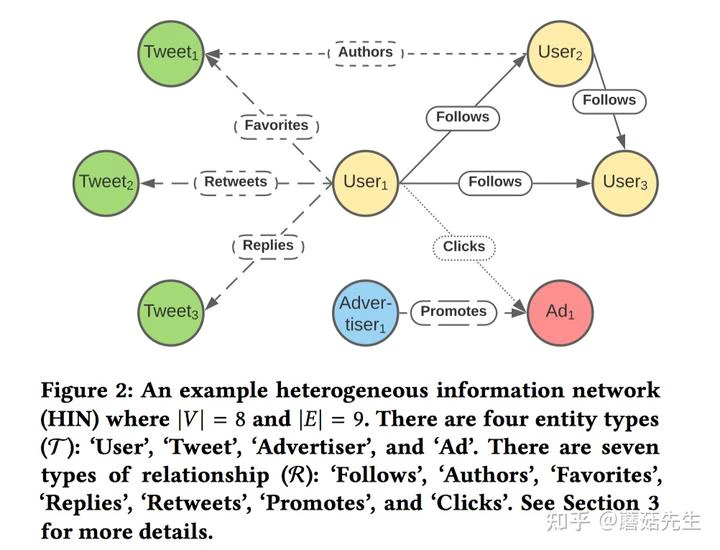
- 稠密嵌入:使用TwHIN[8]做user、twitter的稠密嵌入表征。异构图如下图所示,得到的稠密表征计算相似度就可以用于图召回。这个部分源码开源在the-algorithm-ml中,参见[3]。下次会在系列3中进行分享。
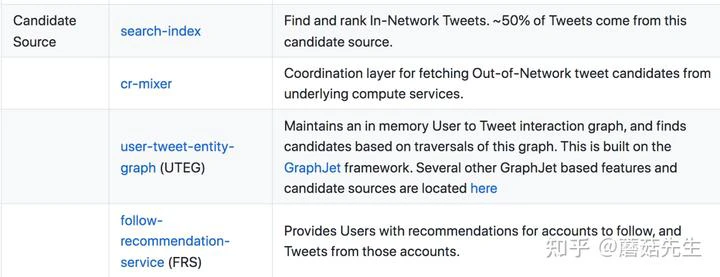
除此之外,还提到了CR-Mixer,是个协调层,代理执行Out-of-Network多路召回,调用底层的计算服务,包括:源信号抽取(source signal extraction), 召回结果生成(candidate generation), 过滤(filtering)和粗排(light ranker)。个人理解这个服务是在多路召回后、精排前,主要用于调用多种召回服务、多路合并和粗排。
除了推文的推荐, 还介绍了推人服务(following-recommendation-service(FRS),用于推荐作者,也是一个小的推荐系统,流程基本同主推荐系统,包括召回,排序,过滤,推荐理由,排序主要预测关注概率以及关注后进作者主页正向交互的概率,二者加权融合。
到此,我们来一览Twitter召回的核心组件:

粗排
本质是个引擎侧召回通道的海选粗排。包括2个,1个是Early Bird的in-network召回后海选粗排模型、1个是UTEG召回(GraphJet图游走)后的海选粗排模型,二者差异不大,只是特征不一样。
很老的LR模型,预测用户会交互twitter的概率,这个模型内部正准备重构。整体架构如下所示:
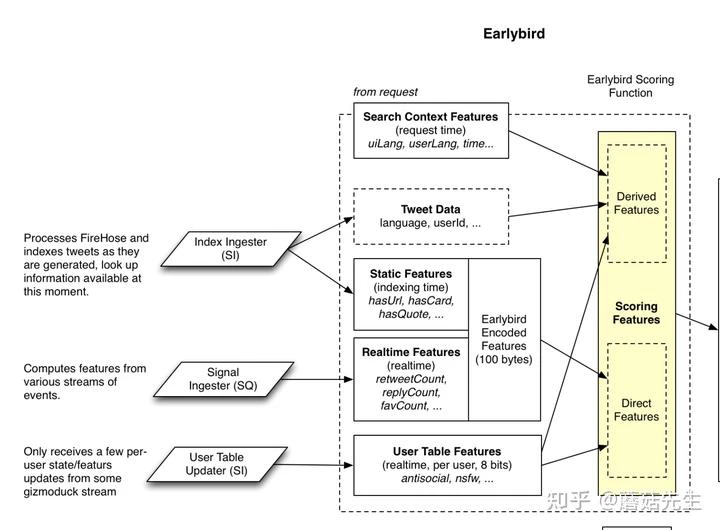
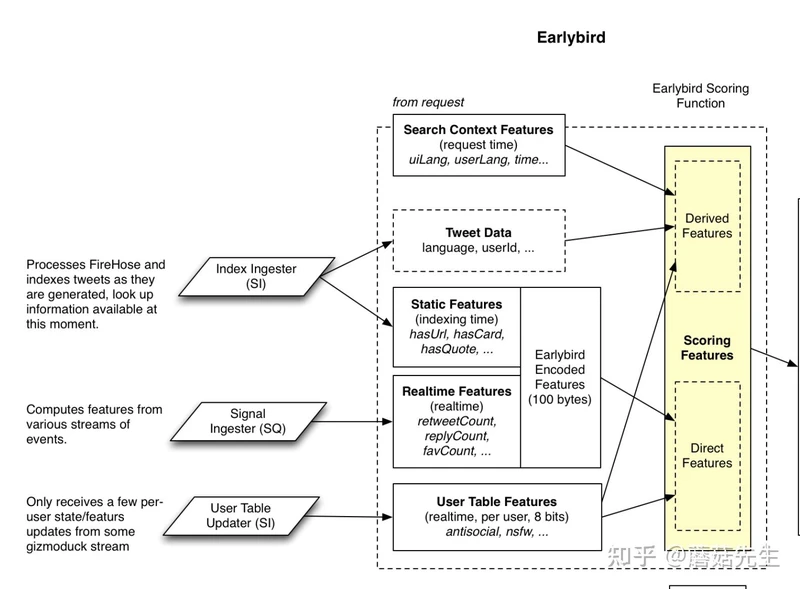
LR的特征涵盖了用户侧特征(tweepcred: pagerank做声誉预估,粉丝数等)、tweet特征(包括静态文本质量、实时转发、回复、关注等)以及上下文特征(用户语言)。
对交互正样本会做加权损失训练,比如:点击的权重为1,点赞的权重为2等。
在blog[1]中提到in-network召回的粗排模型用到了RealGraph,出自Twitter在KDD 2014自研的工作:RealGraph: User Interaction Prediction at Twitter[4],本质是个LR逻辑回归模型,但预测是用户和用户的交互概率:
- 输入:RealGraph是一个有向带权同构graph,节点是Twitter的用户、边是用户与用户的交互关系。由历史行为构成。
- 输出:目标是预测用户和用户交互的概率,本质是个链接预测的任务。
- 模型:会基于RealGraph以及边的特征,使用逻辑回归模型来训练,并预测交互概率。
- 用法:基于预测得到的交互概率,交互概率越高的用户,其推文就会更多地推荐给你。
这个地方和github的代码里的real-graph对应不起来,有点出路。个人感觉可能real-graph得到的user-user probability一方面可以用于推人服务的粗排,另一方面也可以作为user-author of twitter的交叉特征,作为LR粗排模型的输入。
这块特征工程可以研究下,可能有一些实践经验收获。
看起来Twitter没有专门建设多路召回合并后的粗排模型。推测Twitter的架构中,核心召回路in-network、out-network过海选粗排模型,各挑选750个结果,一共1500个结果进精排。
精排
parallel masknet,出自新浪微博(tql)发表在DLP-KDD 2021上的:MaskNet: Introducing Feature-Wise Multiplication to CTR Ranking Models by Instance-Guided Mask[10]。


精排打分候选集数量1500,是个多目标模型。48M参数的神经网络实现的(也太小了吧!),该网络在推特交互数据训练,优化如点赞、转发和回复等目标,考虑了数千个特征,并输出十个Label,为每条推文打分,代表交互的概率,根据这些分数对推文进行融合排序。一共10个目标,下次会细致分享Twitter的精排模型以及源码。
预测时使用简单加权求和融合排序,看起来是手拍的。
到此可以一览Twitter Ranking的核心组件:

重排
主要目的是做过滤以及支持一些产品Feature,启发式规则导向:
- 可见性:屏蔽的推文、作者等。
- 作者多样性:保证作者多样性。
- 内容平衡:In-Network推文和Out-of-Network推文的控比。
- 基于反馈的疲劳内容:用户有负反馈的时候,做些干预策略。
- 二跳人脉过滤:排除与推文没有二级关联的out-of-network推文。 不会推荐跳数过多的无关用户。
- 推文以及回复:推文以及推文的回复上下文展示。
- 更新检测:确定当前设备上的推文是否过时,并发送指令以将其替换为编辑后的版本。
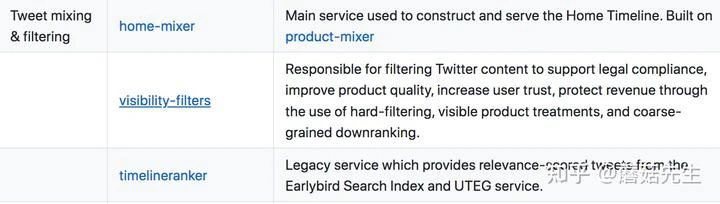
混排
负责主页混排(Homepage Mixer),包括:推文、广告、关注作者、Onboarding prompts等。
上面的流程每天运行大约 50 亿次,平均完成时间不到 1.5 秒。单个管道执行需要 220 秒的 CPU 时间,几乎是在应用程序上看到的延迟的 150 倍。
到此可以一览Twitter的重排、混排层核心组件:
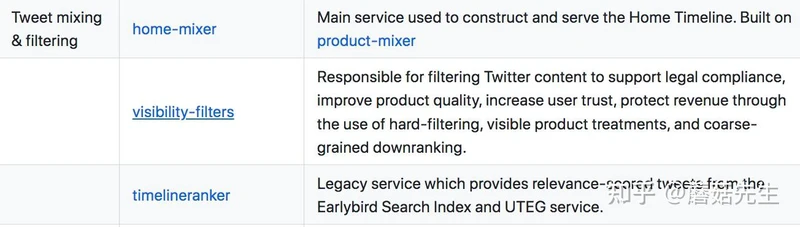
基建
- 模型serving服务:Navi,High performance, machine learning model serving written in Rust.
- Feeds信息流推荐框架:Product-mixer,Software framework for building feeds of content.
- 机器学习训练框架:twml,基于TF-1,即将废弃的机器学习框架,目前用于训练粗排Earlybird light ranker。
核心基建如下:


Twitter 2.0 透明新时代:A new era of transparency for Twitter
不得不说开源是个很大胆的举措。最后我们来一睹马斯克对于twitter 2.0的愿景[11],全新篇章开启。
在 Twitter 2.0,我们相信作为互联网的城市广场,我们有责任让我们的平台透明化。因此,今天我们迈出了迈向透明新时代的第一步,并向全球社区开放了我们的大部分源代码。
在 GitHub 上,您会发现两个新的代码库(main repo、ml repo),包含了 Twitter 的许多源代码,包括我们的推荐算法,它负责分发您在 For You 时间轴上看到的推文。对于此版本,我们的目标是尽可能提高透明度,同时去掉了一些可能被不法分子利用的代码:这些代码主要用于保护用户安全和隐私、保护我们的平台免受不良行为者侵害,防止我们打击儿童性剥削和性操纵的努力被破坏。也去掉了一些广告推荐的算法。我们还采取了额外措施来确保用户安全和隐私得到保护,因此不发布与 Twitter 算法相关的训练数据或模型权重。
这是我们以这种方式变得更加透明的第一步,我们计划继续共享更多不会对 Twitter 或我们平台上的人构成重大风险的代码。
我们邀请社区提交 GitHub 问题和PR,以获取有关改进推荐算法的建议。我们正在开发工具来管理这些建议并将同步到我们内部代码库。任何安全问题或问题都可通过 HackerOne 提交给我们的官方漏洞赏金计划。我们希望受益于全球社区的集体智慧和专业知识,帮助我们发现问题并提出改进建议,最终打造更好的 Twitter。
作为互联网的城市广场,我们最终这样做是为了提高透明度并与我们的用户、客户和公众建立信任。随着我们在这一领域取得进展,我们将继续分享更新。
References
[4] KDD 2014:RealGraph: User Interaction Prediction at Twitter
[5] VLDB 2016:GraphJet: Real-Time Content Recommendations at Twitter
[7] KDD 2020:SimClusters: Community-Based Representations for Heterogeneous Recommendations at Twitter
[8] KDD 2022:TwHIN: Embedding the Twitter Heterogeneous Information Network for Personalized Recommendation
[10] DLP-KDD 2021:MaskNet: Introducing Feature-Wise Multiplication to CTR Ranking Models by Instance-Guided Mask

