
现在有很多股票市场,我们的研究落脚点将是“纽约证券交易所”。为什么?因为它是最大的股票市场,大多数相关研究都以它为研究对象。现在,在继续我们的研究之前,需要理解一个术语,它是“道琼斯工业平均指数”,或者简称为“道琼斯指数”。
道琼斯工业平均指数是纽约证券交易所和纳斯达克交易的30只重要股票的价格加权平均值。道琼斯工业平均指数是查尔斯道在1896年发明的。
道琼斯工业平均指数通常被称为“道琼斯”, 道琼斯工业平均指数(DJIA)包括世界上最老、最受关注的一部分公司,有通用电气公司、华特迪士尼公司、埃克森美孚公司以及微软等公司。电视网络中的通常指的是道琼斯指数。
所以道琼斯指数为我们就研究股票市场是高走还是低走提供了一个很好的思路。那么DJIA到底衡量什么?它本身只是前30大公司股票价格的加权平均值,其中,价值更高的股票被赋予更大的权重,而最终的结果将被标准化以剔除偶然性事件。因此,它本身就是一个价格。
因此,有了DJIA,我们现在就有了一个可靠的方法去了解市场一天的表现。现在我们需要的是一种能够挖掘公众意见的方式,为此我们借助Twitter。
Twitter情绪分析
机器能理解情感吗?不,他们不能,直到现在,我们不是指完美的不(而是相当不完美的不),因为机器现在可以理解各种各样的情感(尽管不是完美和可靠的),并且很容易被愚弄/迷惑。
使用机器学习可以测量某段文本中表达的情绪(或情感)。但是精确度还有待提高。但是,如果情感被明确表达,并且语言上的含义并没有被扭曲,那么我们可以建立一个可靠的情感分析模型。这是Bollen从推特上获得情绪表达的载体想法。
情感分析是机器学习中一个非常重要的应用,许多不同的(指的是很多)算法已经被用于从文本中获取情感这一现象就不足为奇了。让我们来看一个最简单和直观的算法。考虑一个文本:
“埃隆.马斯克的个性和他的人生哲学给我留下了非常深刻的印象,难怪特斯拉和太空探索技术公司(spaceX)做出了如此伟大的努力。”
“埃隆.马斯克的个性和他的人生哲学给我留下了非常深刻的印象,难怪特斯拉和太空探索技术公司(spaceX)做出了如此伟大的努力。”
我们的算法将只关注重要的单词,如“非常”、“印象深刻”等。(而不是像“我”、“是”等词。我们的算法可能不知道spaceX、 Elon、Musk, 所以这些词可能会被忽略掉)。现在,考虑到该算法之前已经遍历过正面积极的词(在该训练文本的时候),并发现诸如“漂亮”“印象深刻”“伟大”这样的词大多与正面情绪有关。因此我们的算法可能会将文本标记为积极。
这是Textblob (文本分析工具:https://textblob.readthedocs.io/en/dev/)所采用的方法,它非常简单,Textblob基于朴素贝叶斯算法工作。朴素贝叶斯算法是一种非常简单的算法,考虑到它的简单性,它给出的结果会很大。因此这个算法的思路是——考虑到每个单词所关联的文档类型,给每个单词赋予一个分数。从而出现在正面文本中的单词比出现在负面文本中的单词更有可能有更高(或更积极)的分数。因此如果积极的词出现在文档中,那么这个文本更有可能是正面的。因此,每个单词都有自己的分数,然后对这些分数进行平均,以获得文档的情感倾向。
当然,这种方法并不理想,尤其是在复杂的文档上,这样的方法会产生非常差的结果。因此,大多数研究者也会使用更复杂的分类器(如SVMs,即支持向量机)来建立情感分析模型。
Bollen使用了两种工具进行情感挖掘,一种是意见查找器,另一种是谷歌公司推出的关于情绪状态的个人资料服务。这些天我并没有见过很多人使用意见查找器,当然这个工具对于本博客来说也不是很重要,所以我们将把它放在谷歌情绪状态简介(或GPOMS)上。
GPOMS是一种工具,它可以帮助你准确地检测文本中表达的情绪。它基于情绪状态,由65或37个问题组成的调查问卷,而这将取决于你选择哪一个。对于每一个问题,你都用以下的词来表明你的感受——“一点也不”、“一点”、“适度”、“相当多”、“极度”。 因此,举个例子,对于“遗憾”的问题,你会指出你作为上述状态之一的感觉, 它会用一个标准来转换成分数,你的情感倾向将会根据你的反应来进行计算。这里有一个测试链接:https://www.brianmac.co.uk/poms.htm
那么,GPOMS如何使用POMS从文本中预测情绪呢?你可以点击这个谷歌连接。Bollen使用了谷歌发布的一个数据集。这个数据集包括从1万亿个英文网页文本中提取的n-gram的频率来计数。你可以在这里试试。那么bollen做了什么:他将POMS调查问卷中的每个单词与google n-gram数据集中的n-gram相关联,然后将最频繁出现的N -gram分成标记。现在这些单词中的每一个都有与之相关联的情绪,并且可以基于这些单词出现的情况来给它们一个加权分数,并根据这些词在文本中的出现的部分来用情感进行标记。
以上是我们对Bollen在论文中对这一方法解释的理解:
因此,词典中964个术语的扩充使得GPOMS得以在推文中捕捉更多自然流出的情绪术语,并将它们映射到各自的POMS情绪维度中。我们将每条推文中使用的术语与这一词典进行匹配。匹配n-gram术语的每个推文术语被映射回其原始POMS术语(根据其共同权重),并通过POMS评分表映射回其各自的POMS维度。因此,每个POMS情绪维度的得分被确定为与GPOMS词典匹配的每个推词的共现权重的加权和。
因此,词典中964个术语的扩充使得GPOMS得以在推文中捕捉更多自然流出的情绪术语,并将它们映射到各自的POMS情绪维度中。我们将每条推文中使用的术语与这一词典进行匹配。匹配n-gram术语的每个推文术语被映射回其原始POMS术语(根据其共同权重),并通过POMS评分表映射回其各自的POMS维度。因此,每个POMS情绪维度的得分被确定为与GPOMS词典匹配的每个推词的共现权重的加权和。
不幸的是,GPOMS不再可被自由获取,现在它是一个封闭的源代码工具(http://101.96.10.75/cs229.stanford.edu/proj2011/GoelMittal-StockMarketPredictionUsingTwitterSentimentAnalysis.pdf)。Goel- Mittal用一种简单得多的方法建立了一个类似的模型(尽管不太准确)。他们使用POMS问卷中出现的单词的同义词,然后将它们映射到文本中。
根据他的GPOMS模型和意见调查者Bollen发现的人们的情绪倾向,得到的结果如下:

我们现在已经完成了四个部分中的两个,我们知道了如何衡量公众的情绪和市场的情绪。现在我们可以继续证明这两者之间确实是关联的。
“时间序列”间的相关性
如上图所示,我们已经获得了关于人们情绪的时间序列,类似的DJIA分数时间序列可以很容易地获得。现在,我们需要寻找一种方法来证明这些是相互关联的,或者人们的情绪(从推特上挖掘出来的)导致了股票市场的变化。
我们用格兰杰因果关系(Granger causality)来对它进行处理。那么到底什么是格兰杰因果检验呢?根据 Schoaropedia 的文章(http://www.scholarpedia.org/article/Granger_causality)
格兰杰因果关系(Granger causality)是基于预测的因果关系的统计概念。根据格兰杰因果关系,如果信号X1是信号X2的格兰杰原因(或G-causes),则X1的过去值应该包含有助于预测X2的信息,而不仅仅是X2过去值中包含的信息。它的数学公式基于随机过程的线性回归模型( Granger 1969 )。非线性情况存在更复杂的扩展形式,然而这些扩展形式在实践中往往更难应用。
所以,如果我们有两个时间序列,比如X1和X2,我们可以证明X2依赖于它的历史值,即:
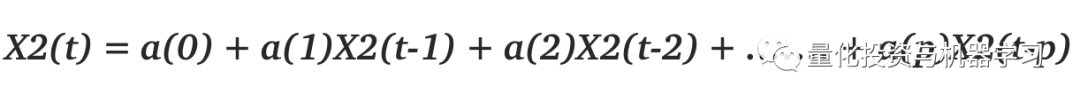
这里, 至少有一个常数 不为零,那么我们可以说 取决于其历史值,已知上述关系后,如果 中至少有一个不为零,那么以下关系成立:
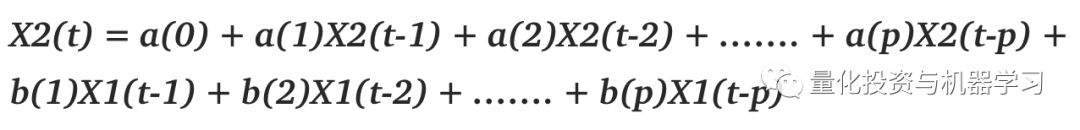
那么我们可以说X1是X2的格兰杰原因, 或者X1有预测X2的可能性。请参考这段视频可以更好地理解格兰杰因果关系。
在做了二元格兰杰因果分析后,Bollen发现,在六种情绪状态(即平静、警觉、肯定、重要、善良和快乐)中,只有一种情绪状态,即“平静”情绪状态与股票市场的Granger因果关系最大,从2天到6天不等,另外四种情绪维度与股票市场没有显著的因果关系。
因此,Bollen绘制了“平静”的时间序列(滞后3天)和DJIA时间序列,以显示两者之间的相关性:
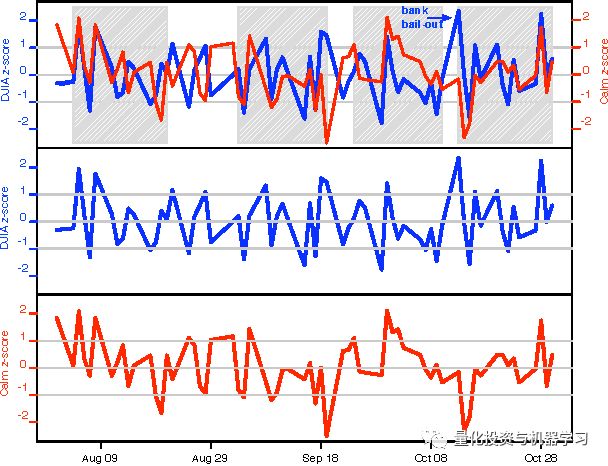
阴影部分显示了具有显著相关性的部分。我们应该记住,平静图滞后3天,因此Twitter的数据不是可以同步对市场进行预测,而是在3天前预测市场。如果我们仔细观察的话,我们可以看到这个图中存在大量的相关性,因此现在我们可以确定两个时间序列之间存在相关性。我们可以利用这些信息来预测股票市场,以及见证我们预测的准确性有多高。
预测股票市场
现在,对于试金石数据,我们能根据现有的Twitter预测以前看不见的股票市场的将来趋势吗?
为了预测股票市场,Bollen使用了一种叫做自组织模糊神经网络(SOFNN)的算法,他们使用了五层混合SOFNN模型来预测股票市场,并获得了令人印象深刻的结果。他们使用了不同的数据排列方式,例如,只有平静,平静和快乐交织等。他们在以非线性方式将平静和快乐结合在一起后获得的最佳准确率为87.6 %。
那么,到底什么是SOFNN?(http://www.scholarpedia.org/article/Fuzzy_neural_network)根据这篇sholaropedia的学术论文,结合模糊逻辑和神经网络的优点,为类似的任务创建了一个非常好的模型。这两个主题都超出了本文的范围。因此,我们将只简要讨论他们。
在进行计算机操作时,我们主要处理的是布尔逻辑或二进制逻辑,即任何实体都可认为0或1。但是这种类型的逻辑在现实世界的许多场景中并不适用,因为我们一般会面临超过一个的结果,例如,游戏的结果主要是赢或输,但也可能是平局,或者也可能需要考虑到赢的差距,因此在0和1这两者之间可能会有更多的状态。对我们来说,这似乎比二进制(又称黑白)方法更自然,也更有助于模拟现实世界的情况。这种模糊方法是模糊逻辑背后的逻辑,你可以在这里读到更多(http://www.scholarpedia.org/article/Fuzzy_neural_network)
如果你没听说过神经网络,那么现在神经网络是个时髦的词。是时候了解一些相关的博客了。基本上,这是一个试图模仿人脑内部神经元的数学模型。
以下是sholaropedia对混合模糊神经网络的一个很好的解释:
混合神经模糊系统是同质的,一般而言,它与神经网络类似。这里,模糊系统被解释为一种特殊的神经网络。这种混合NFS(神经模糊系统)的优点在于模糊系统和神经网络不必相互通信的架构。它们是一个完全融合的实体。这些系统可以在线或离线学习。
模糊系统的规则库被解释为一种神经网络。以模糊集为权重,而输入和输出变量以及规则则被构建成神经元。在学习步骤中可以包括或剔除神经元。最后,神经元网络代表了模糊知识库。 显然, 这两个基础系统的主要缺点都因此被克服了。
混合神经模糊系统是同质的,一般而言,它与神经网络类似。这里,模糊系统被解释为一种特殊的神经网络。这种混合NFS(神经模糊系统)的优点在于模糊系统和神经网络不必相互通信的架构。它们是一个完全融合的实体。这些系统可以在线或离线学习。
模糊系统的规则库被解释为一种神经网络。以模糊集为权重,而输入和输出变量以及规则则被构建成神经元。在学习步骤中可以包括或剔除神经元。最后,神经元网络代表了模糊知识库。 显然, 这两个基础系统的主要缺点都因此被克服了。
综合
以上四个部分试图用来解释用于构建Bollen提出的模型的较小部分。现在,我们将研究的最终模型,来更好地理解可用于预测股票市场的模型:
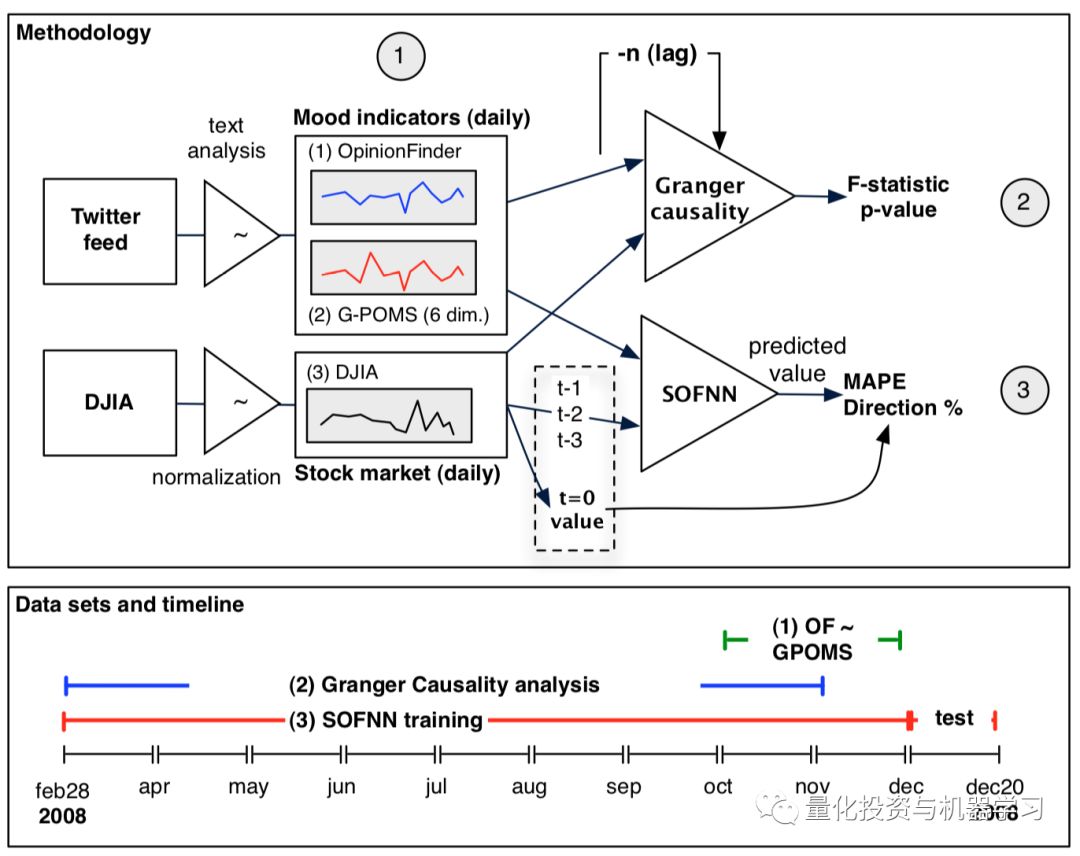
首先,将来自于推特和DJIA中的原始数据进行提取和处理,然后使用情绪分析模型Opinion Finder和GPOMS对推特数据进行Granger因果检验,以证明推特上表达的情绪确实与DJIA值有一定的相关性。一旦上述情况成立,我们接下来就可以开始用SOFNN模型预测股市了。
参考
[1] Bollen, J, Mao, H., Zeng, X.: Twitter mood predicts the stock market. Jourmal of Computational Science,2(1),1-8(2011).
[2] Mittal, Anshul, and Arpit Goel. "Stock prediction using twitter sentiment analysis." Stanford CS229(2011)
http://cs229.stanford.edu/proj2011/GoelMia-

