
导读:大家好,我是来自阿里巴巴的魏子珺,今天给大家分享的主题是基于Elasticsearch的指标可观测实践。主要包括以下几部分内容:
- Elasticsearch为什么做时序引擎
- Elasticsearch做时序引擎的挑战
- Elasticsearch 时序引擎特性介绍
- 阿里云基于Elasticsearch TimeStream介绍
01 Elasticsearch为什么做时序引擎
首先看一下Elasticsearch为什么要做时序引擎。
故事要从阿里云和ES(后面文章Elasticsearch统一简称ES)社区的一次沟通会议说起,当时我们在沟通一些ES内核方面的问题,共同说到了ES做指标存储的痛点, ES社区当时已经开始设计时序引擎的文档,我们也在阿里云内部监控发现了很多ES做存储指标的问题。于是双方一拍即合,开始共同建设时序引擎这个项目。时序引擎相关的Issue:记录了所有时序引擎相关的TODO list。


说到ES做时序引擎,用户们通常会有下面两种对立的声音:
一种是怎么能用ES做时序引擎?肯定要用专业的时序引擎,他们可能不知道ES为什么不能做时序引擎,只是觉得专业的事情要交给专业的人去做。
另外一种是ES本来就可以做时序引擎,为什么还要开发?这些用户可能已经把ES用作了时序引擎的场景。
那么用ES做时序引擎到底会有什么问题?本文就为大家解开谜题。

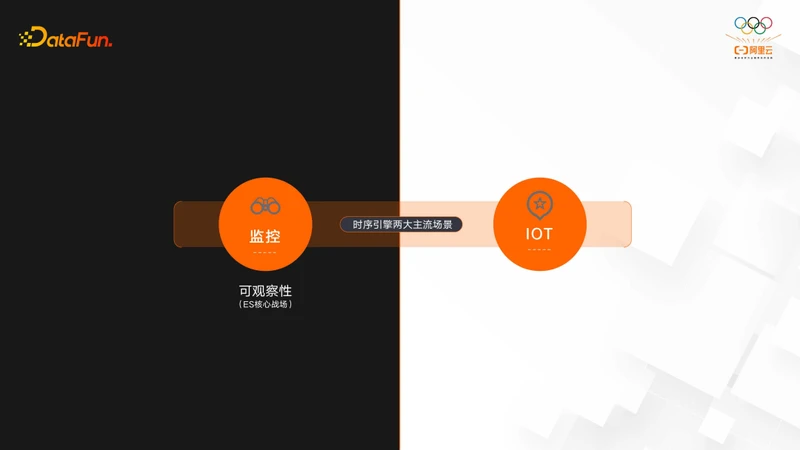
时序引擎有两大主流的场景:
一类是用作监控,这也是可观察性的一个方向,所以这也是ES的核心战场。
另一类是用作IOT场景,IOT场景有大量的设备会产生大量的指标,所以需要一个时序数据库来存储这些数据。


下面简单介绍一下时序引擎。时序引擎应对的是一种特点非常鲜明的场景。
首先,它存储的是采样数据,采样数据是基于稳定频率持续产生的一系列数据,相对应的是基于事件产生的数据,事件型数据是离散、随机产生的,而采样型数据是稳定的,持续产生的。
第二个特点是时序引擎的数据模型非常固定,一般都由时间、维度、指标三类字段组成。
第三个特点是时间线的概念,图中的纵坐标是时间线id,他是由维度组成的,一般是保持不变的。横坐标是指标数据,会随着时间不停地变化,这就组成了时间线的概念。
第四个特点,时序引擎存储的数据没有波峰波谷,7*24小时都在稳定的产生数据,跟他相对应的事件型数据一般根据业务的高峰低峰会有起伏。
第五个特点是时序引擎是垂直写,水平查,始终都在写最新的数据,查询会基于一个时间段去做一些聚合型的分析。
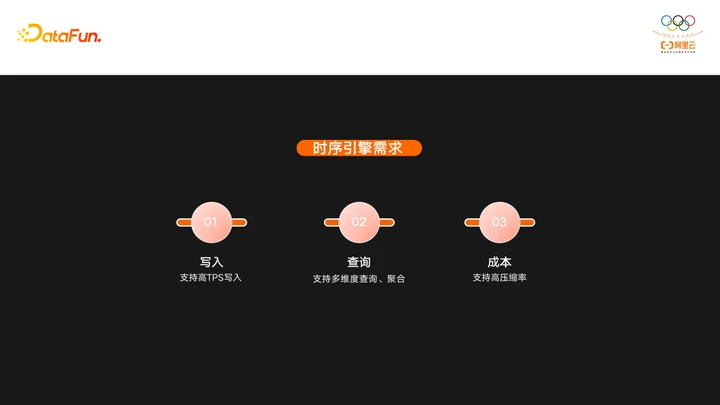
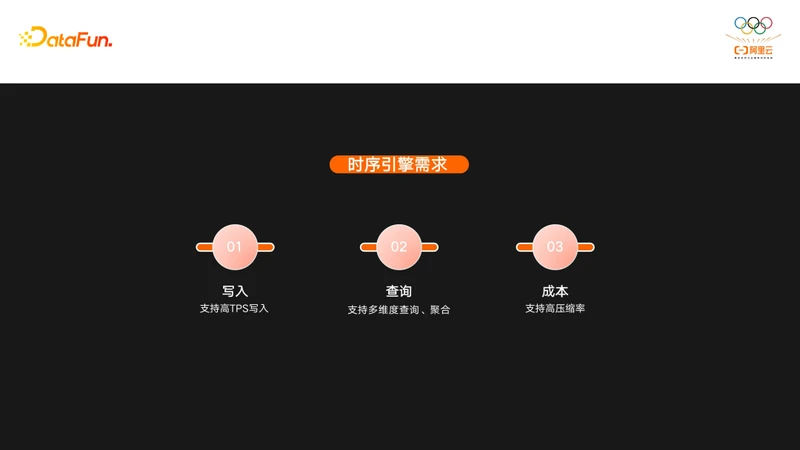
基于时序引擎鲜明的特点,时序引擎主要有下面几个需求:
- 在写入方面,时序引擎需要支持高TPS写入,因为他面对的场景无论是监控还是IOT都有大量的设备在持续不断的产生数据。
- 第二点是查询方面,时序引擎一般都是针对大量的数据去做多维度聚合,而不是单纯去查某一些点的数据。
- 第三是成本方面,由于时序引擎写入量非常大,所以存储在时序引擎上的数据量是非常大的,一般来说数据重复度非常高,而且特点也很鲜明,所以针对性做一些压缩可以极大的降低这部分数据的存储成本。
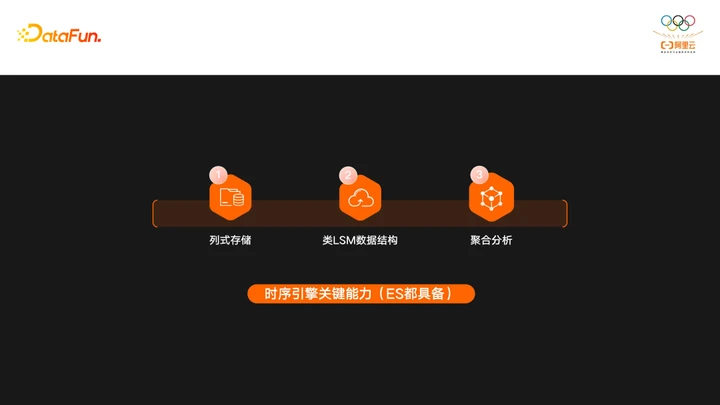
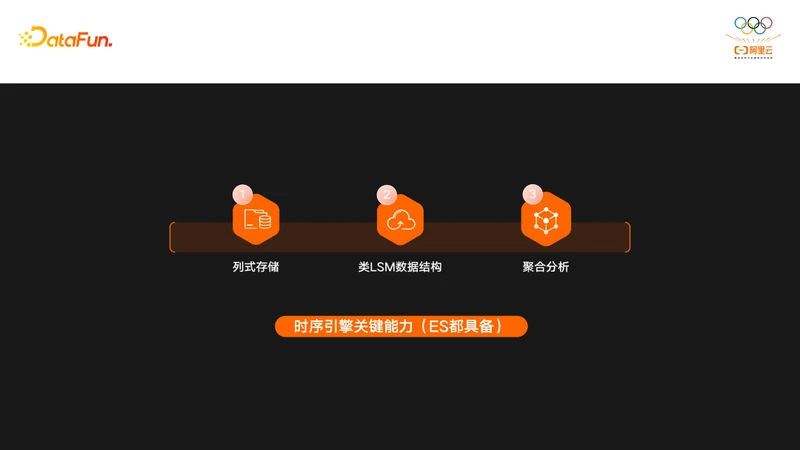
针对上面的需求,时序引擎需要三大关键能力:
- 首先是列式存储,跟他相对的是行式存储,由于时序引擎一般都是分析型需求,而且都是对单个指标的查询,所以如果用行式存储的话会有大量的无效IO,所以一般都得使用列式存储,而且列式存储对压缩也非常友好,这就是为什么很多早期时序引擎都是基于HBase构建的。
- 第二个关键能力是类LSM数据结构,这类数据结构可以很好地支持高吞吐量的写入。
- 第三个是聚合分析,对时序引擎的查询都是一些分析型的需求,所以需要时序引擎支持很好的分析能力,早期的HBase不支持分析,所以都是时序引擎在HBase之上做了支持分析的能力。
这三类能力ES都是具备的,所以说ES没有道理不去做时序引擎。
--
02 Elasticsearch做时序引擎的挑战
接下来介绍一下用ES做时序引擎的挑战。


目前用ES做时序引擎会面临三类痛点:使用门槛过高,查询慢且复杂,以及成本过大。
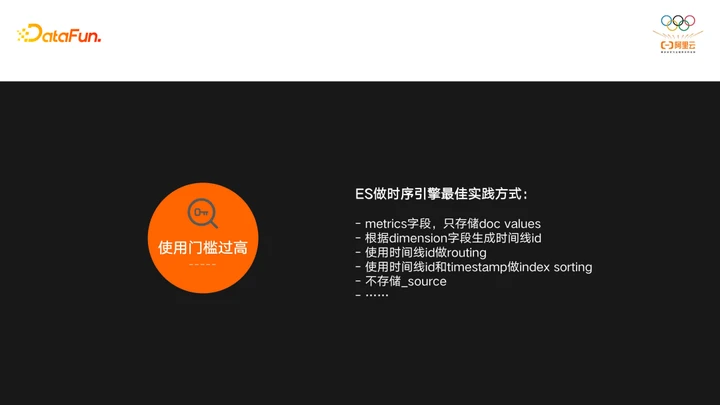

由于ES的定位还是一个通用的搜索引擎,所以用户如果想把ES用作时序引擎的最佳实践,需要对ES有深入了解,做很多定制化的优化和在业务侧做很多开发才能使用,图中列出来的这些内容就是ES做时序引擎的最佳实践。


第二个是查询方面的问题,下面用两个例子来看这个问题,这是一个查看指标up监控曲线的需求,PromQL只需要一个“up”关键字就可以完成这个需求,对ES来说他的DSL需要写quary、 aggs等复杂的语法才能够完成。
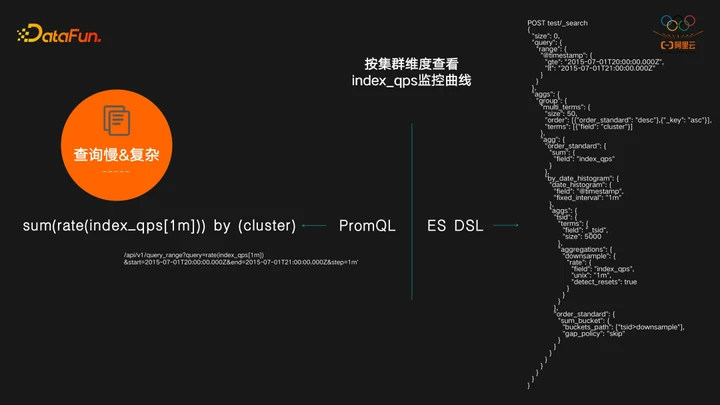
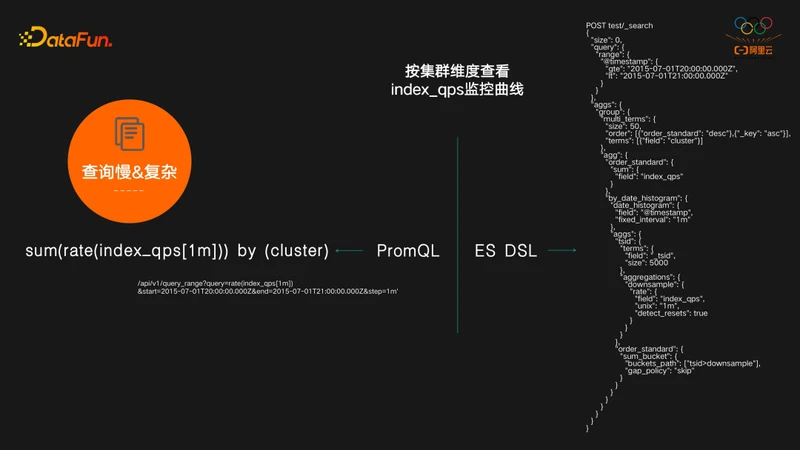
第二个例子,按集群维度查看index_qps监控曲线,对 PromQL来说,先对指标做一次rate,再对cluster做一次sum by就可以完成这个需求,而对ES来说,需要写query和很复杂的aggs,甚至还用到了ES最复杂的pipeline aggs,功能虽然OK,但性能非常低下。
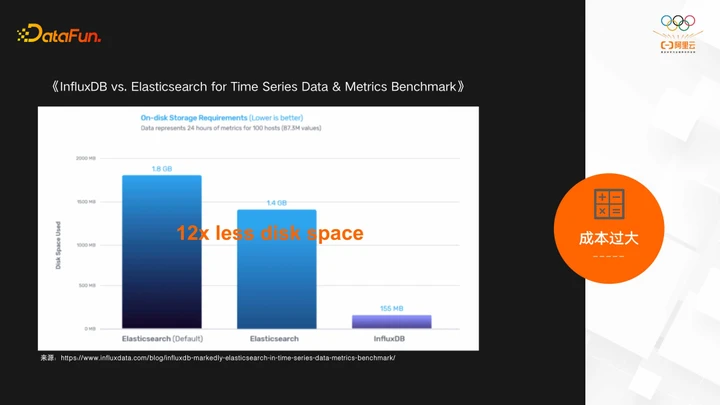
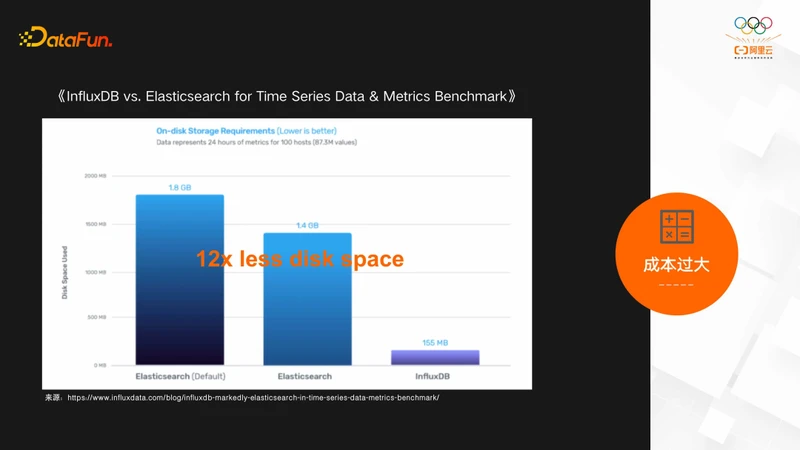
再看成本过大的问题,InfluxDB官方给出了ES 做时序引擎的benchmark的对比,这里贴出来了一个存储容量对比的结果,可以看到存同样的数据存储ES 容量是InfluxDB的12倍。
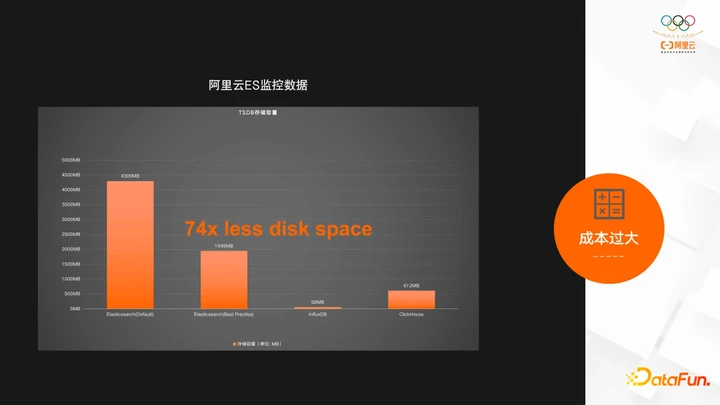

我们也用阿里云监控存储ES的数据来进行了对比,可以看到更夸张的结果,ES是InfluxDB存储容量的74倍,即使ES做了在时序场景的最佳实践,容量减半,也还是InfluxDB的30多倍。
所以可以看到包括使用门槛,查询、容量的问题,这些虽然都不影响功能,但是相比其他的时序引擎,他的缺点就非常明显,这也回答了前面的问题,ES也能做时序引擎,但是效率非常的低下。
--
03 Elasticsearch 时序引擎特性介绍
接下来看ES 时序引擎项目,以及阿里云ES TimeStream怎么解决这些问题。先来看下社区的优化。


关于Index Level的优化,这里列出了 ES 做时序引擎的几个优化的关键点:
- Setting中增加了一个index.mode=time_series的设置,这个设置告诉ES在内部去实现时序场景的最佳实践。这个配置要结合一些其他配置一起生效。
- Mapping 字段配置增加了2个关键字:time_series_dimension和time_series_metric,这两个设置是为了告诉ES哪些字段用作维度字段,哪些字段用作指标字段,有这两个配置再结合index.mode=time_series,ES会把所有的维度字段生成一个_tsid(时间线ID)内部字段,用_tsid和timestamp去做 index sorting。
- 最下面可以看到一个@timestamp的字段,如果设置了index.mode=time_series时,这个字段是无需设置的,索引会自动生成一个@timestamp的时间字段。
- 中间Mapping里面还有一个” {"_source":{"syntheic":true}}”的设置,这个设置可以告诉ES可以无需存原始数据_source。需要看明细数据时,ES内部使用列式存储的docvalues数据生成原始的_source,这样就可以极大地节省了ES的存储空间。
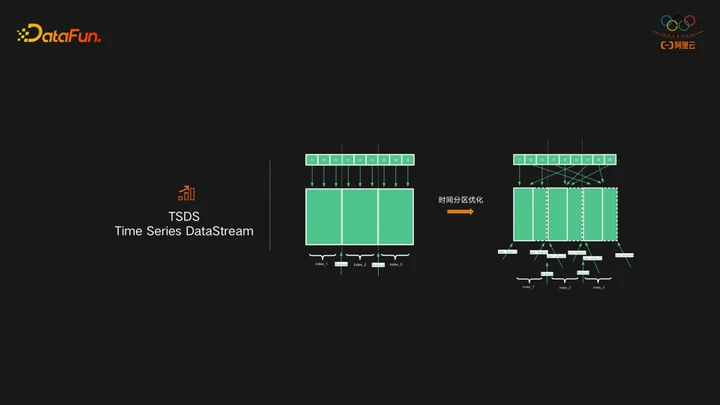
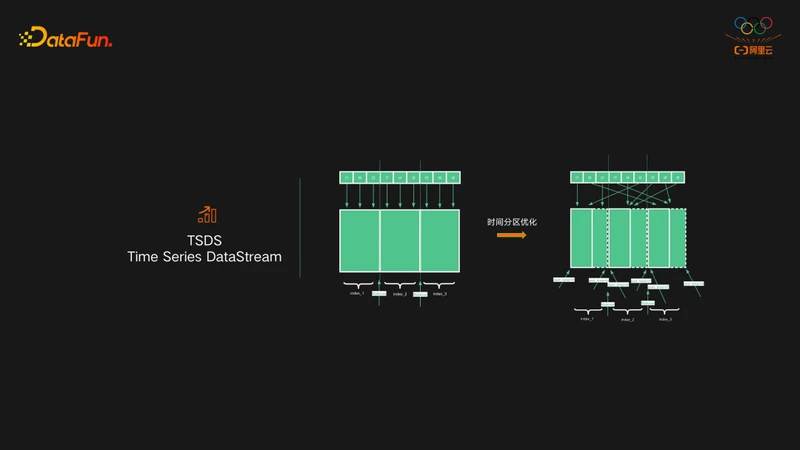
ES的另一个优化,是使用TSDS作为时序场景的使用方式,TSDS全称是Time Series DataStream。DataStream是对index做的一层封装,主要解决的是ES索引无限膨胀,以及无法过期历史数据等问题。TSDS相比普通的DataStream主要区别是时间分区的优化,普通的DataStream索引在写入数据的时候,无论是新数据还是老数据,写入的时候始终都是写入最新的是索引。这样在时序引擎场景中就会带来一个问题,当要对数据按时间分桶的时候,桶内的数据可能会出现在所有的索引中。这里ES对时间分区做了优化,效果是写入的数据按照时间字段进行索引分区。
实现方法如下:
- 索引Settings增加了index.time_series.start_time, index.time_series.end_time两个配置。start_time用来标识索引的起始时间,end_time标识结束时间,索引只允许在时间范围内的数据写入,其中start_time是final类型不能修改,end_time可以动态修改,但是只能修改为比当前值大的value。
- DataStream发现索引模板中配置的是time_series索引,则会自动生成索引的start_time和end_time。DataStream做rollover的时候,上一个索引的end_time,设置为下一个索引的start_time,这样索引不断增加时,索引之间在时间上是无缝衔接的。
TSDS有了时间分区,在做时间范围查询时,只要查询对应时间范围的索引即可,而且TSDS的时间分区,相比普通按天、月、年等固定分区,它是一个弹性分区,可以更好地控制索引元数据数量。
04 阿里云Elasticsearch TimeStream介绍
下面介绍一下阿里云ES TimeStream如何解决ES做时序引擎的问题。
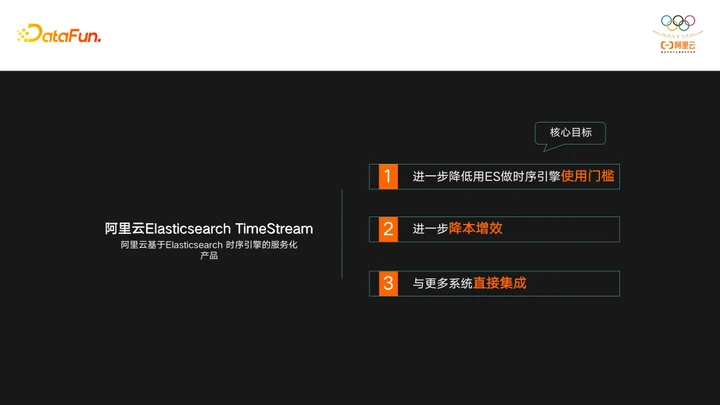
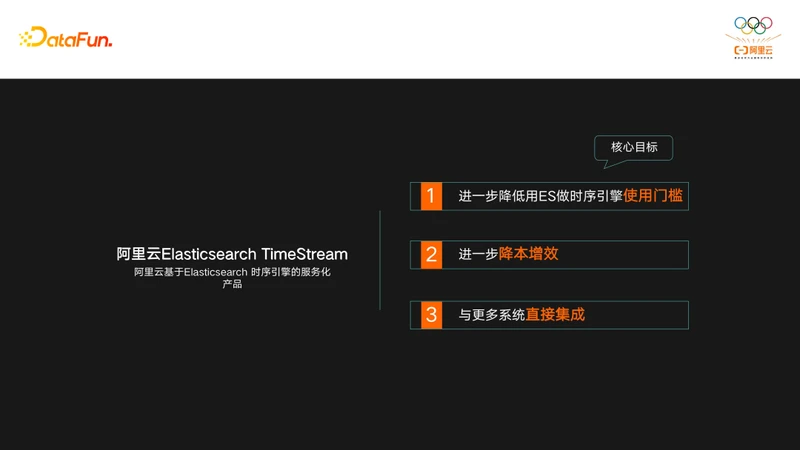
阿里云ES TimeStream,是阿里云基于ES自研的时序引擎,其核心目标主要有下面三个:
- 进一步降低了ES用做时序引擎的使用门槛
- TimeStream结合阿里云ES内核来进一步的降本增效
- TimeStream能够和更多的系统直接集成。


在TimeStream内部定义了时序模型,包括:labels,metrics和timestamp三种类型的字段,在创建TimeStream索引的时候直接使用命令“PUT _time_stream/{name}”即可,如果想做更复杂的配置可以使用ES template的语法。如果想自定义时序模型,那么在创建TimeStream索引时也可以自定义labels和metrics。
TimeStream索引读写数据的方式跟正常索引一样,直接使用ES原生API即可。


再来看一下TimeStream如何降本增效。
前文提到ES存储空间是InfluxDB的74倍,我们进一步分析ES数据存储的占比是怎么样的,发现了两大可以优化的点:
- 首先是在ES做时序场景的数据压缩方面有所欠缺,所以TimeStream在数据压缩上可以极大地降低占用空间。
- 另一点我们发现ES存储时序数据时,存储空间主要来自于元数据字段,如_id, _source等,把这些字段去掉,再通过一些自动生成的方式满足查询需求。
通过数据压缩和减少元数据存储可以极大的降低存储空间。
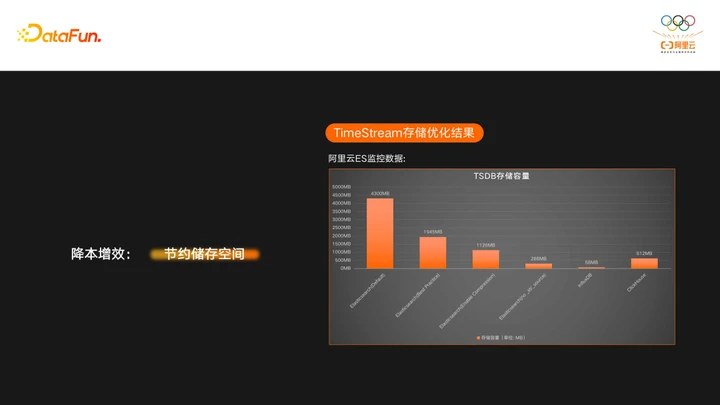
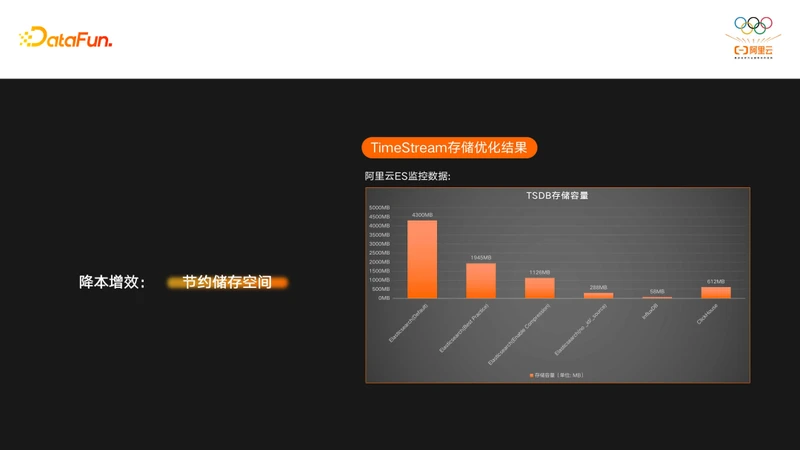
来看一下做了这两部分优化的效果:
存储空间在使用了压缩之后直接从1900多MB降到了1100MB多兆,这降低的800多MB的空间,基本上都是元数据的开销了。我们再将_id和_source去掉之后,又进一步降低到了200多MB,可以看到ES经过优化以后存储空间已经和InfluxDB接近了,在某些场景上会表现的比InfluxDB更好。
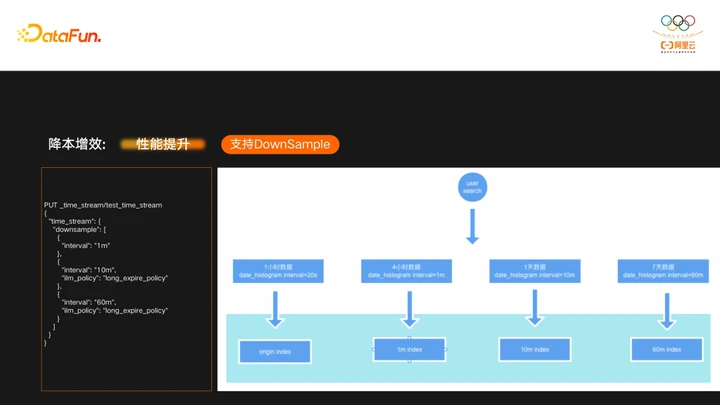
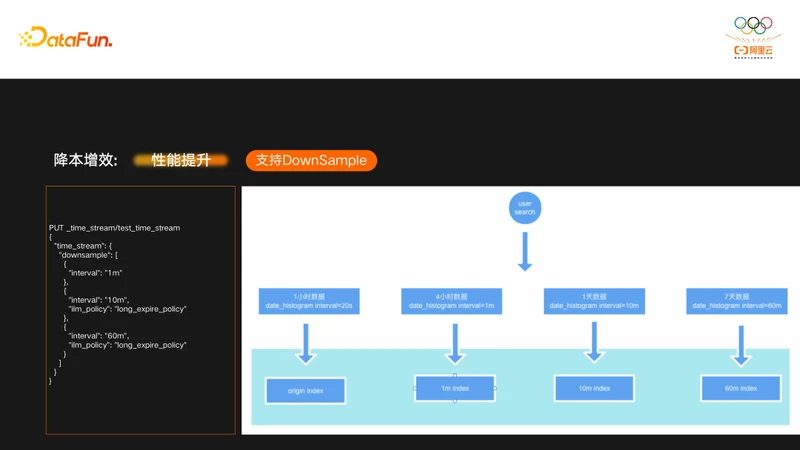
降本增效另一大关键特性是支持DownSample(降采样),DownSample功能通过降低数据的精度,达到降低存储容量,提升查询性能的目的。TimeStream内部直接集成了DownSample功能,在创建索引的时候直接指定DownSample精度,图上示例中给出的精度包括1分钟,10分钟,60分钟,用户在写入原始数据的时候,TimeStream内部还会生成相应的三种精度索引。
用户在查询原始数据的时候,TimeStream内部会根据interval(DSL中date_histogram的interval参数)决定到底该使用什么索引,这时候用户查到的并不是原始索引,而是interval能满足的最粗精度的索引。由于数据量比原始精度小了很多,查询速度也快了很多。
DownSample能降低存储空间,原因是使用DownSample后,原始索引就不需要保存那么长时间了,这样整体存储空间就能得到极大的下降。
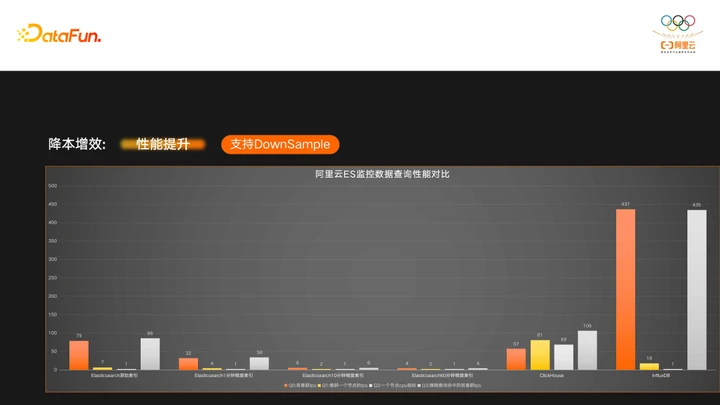
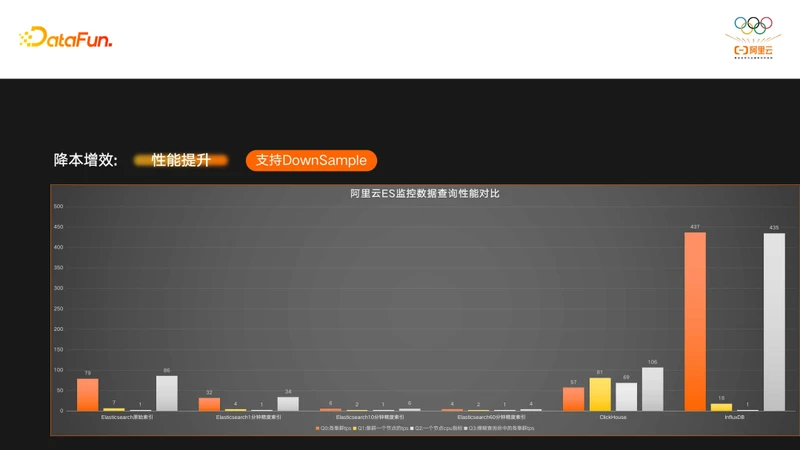
下面我们来看一下DownSample的查询效果:
图中有4个查询Case,可以看到,如果查询到了DownSample的索引,性能相比原始索引有了质的提升。图中也对比了CK和InfluxDB的查询性能,可以看到ES的查询性能是比InfluxDB好的,跟CK相比,部分查询性能优于CK。
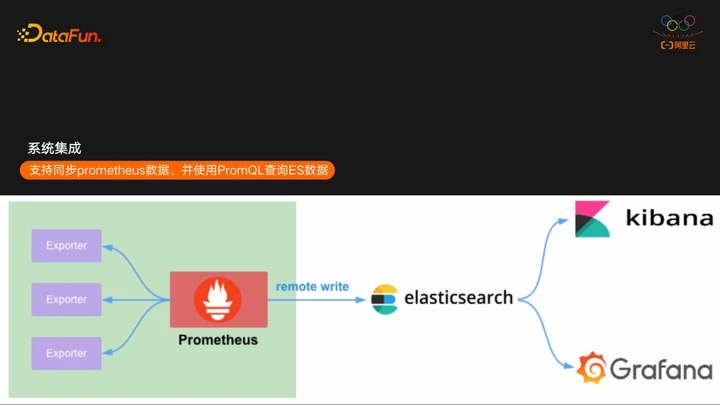
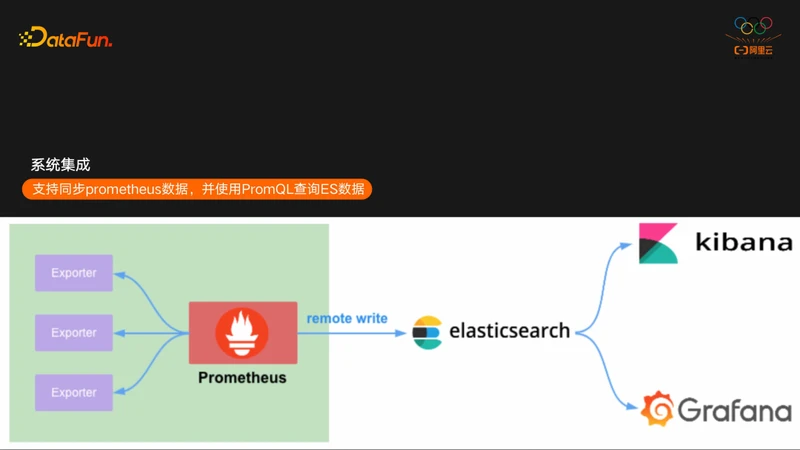
TimeStream的第三大特性是集成方面,目前TimeStream支持了跟Prometheus和Grafana的集成,TimeStream支持了Prometheus的remote write接口,这样可以直接将Prometheus数据同步到ES,作为Prometheus的一个分布式、高可用的远端存储来使用。然后在Grafana直接使用Prometheus的数据源来访问ES。
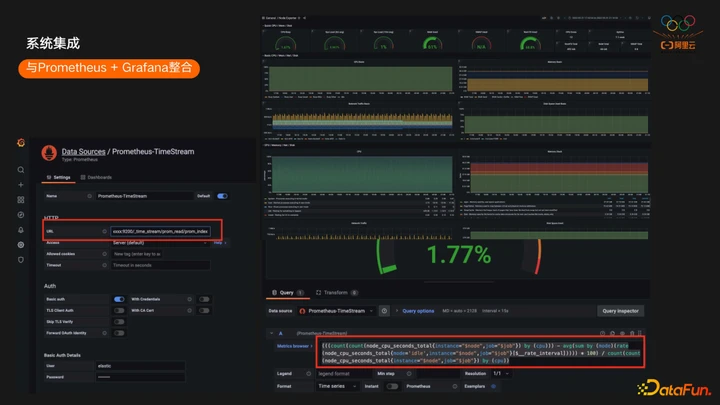
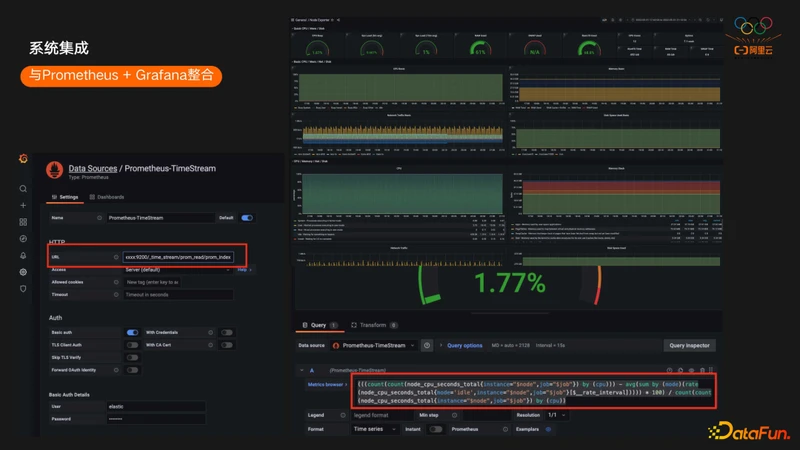
下面看一些示例,用户在选择DataSource的时候,需要选择的是Prometheus的DataSource,地址填写的是ES对应的集群地址。这样可以直接像访问Prometheus一样访问ES。
如果用户用了一些开源的Exporter导入数据,在Grafana直接导入开源Exporter对应的Dashboard即可访问这些数据,与访问原生Prometheus的体验是一模一样的。下面的截图也可以看到ES TimeStream可以支持非常复杂的PromQL,目前时序场景绝大部分的PromQL,常用的function,aggregation都支持。
以上就是阿里云ES TimeStream的介绍,目前ES TimeStream已经在官网上线,更多详细的功能大家可以在阿里云ES官方文档中看到。


最后总结一下用ES做时序引擎。ES 时序引擎项目补齐了ES存储和查询时序数据的短板,让ES可以作为专业的时序引擎使用。
ES还不止于时序引擎,其优势主要在以下三个方面:
- 系统方面:它是分布式、高可用、高可靠、弹性、分层存储、数据备份等功能非常健全的系统;
- 产品方面:整个Elastic Stack技术栈是一个非常完善、丰富的产品;
- 领域方面:支持搜索、可观察性和安全三大领域。
今天的分享就到这里,谢谢大家。
分享嘉宾:魏子珺 阿里云 ES内核专家
编辑整理:陈凯翔 亚厦股份
出品平台:DataFunTalk
分享嘉宾


魏子珺|阿里云 Elasticsearch内核专家
阿里巴巴技术专家,阿里云 Elasticsearch 内核专家,Elasticsearch Top 100 Contributer。
关于我们
DataFun:专注于大数据、人工智能技术应用的分享与交流。发起于2017年,在北京、上海、深圳、杭州等城市举办超过100+线下和100+线上沙龙、论坛及峰会,已邀请超过2000位专家和学者参与分享。其公众号 DataFunTalk 累计生产原创文章700+,百万+阅读,14万+精准粉丝。

