
背景
Kubernetes 问世于 2015年,从一开始秉持着松耦合和可扩展的设计理念,也因此带来了 Kubernetes 生态的蓬勃发展。但这些大部分先限制在单一集群内,然后由于种种原因和目的企业内部创建的集群越来越多,比如
- 单集群故障、异地多机房可用区容灾:Kuberntes 的控制器通过循环机制保证集群状态达到预期状态,但是所有服务都部署在一个集群中,当集群或者机房出现故障时也会导致服务的不可用,对于可用性要求高的服务是无法容忍的。
- 出于敏捷、降本考虑的混合云:企业出于安全性、成本的考量,使用自建+云厂商的混合云部署方式,借助公有云的能力支持快速发展的业务。
- 多云部署:近几年云服务商故障屡见不鲜,为避免单一云服务商的故障引起业务中断;业务拓展需要更广泛的覆盖区域;当地政策对云服务运营商的要求等原因,越来越多的企业选择多云部署。
- 单一集群的承载能力受限:虽然可以可以通过添加删除节点来扩展集群,但是单个集群的计算能力总是优先的。最新的 Kubernetes v1.23 支持的最大节点数 5000;每个节点的 Pod 数量不超过 110;Pod 总数不超过 150000;容器总数不超过 300000。
- 多版本 Kubernetes 集群共存:在替换升级 Kubernetes 版本时,会存在新旧版本集群共存的情况。升级的过程中服务需要从旧集群迁移到新集群。
多集群之后除了提升管理的难度外,首当其冲的就是多集群间的流量调度,这也是多集群部署的基础。没有跨集群的通信,多集群的收益也会大打折扣。
Flomesh 提供了一套跨集群流量的方案,打通多集群连接的“最后一公里“。
概览
这套方案逻辑在逻辑上分为控制平面和数据平面:
- 控制平面是流量调度的“大脑”,监控各个集群的工作负载并作为服务注册中心存在。此外,还会担任类似配置中心的角色,管理和下发流量调度的策略。
- 数据平面由可编程的 Pipy 组成,作为调度策略的执行者管理集群内外及集群间的网络通信。此外,围绕流量提供可观测能力。
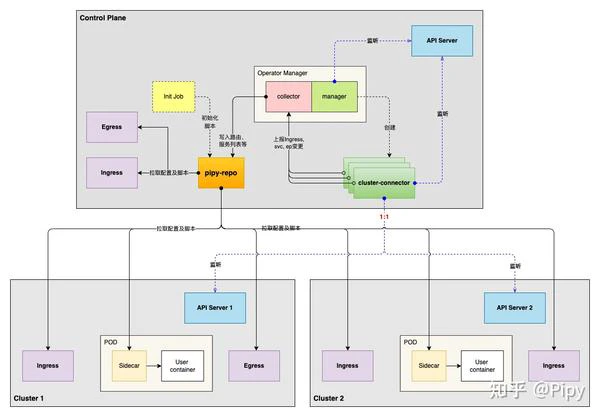
组件与原理
控制平面
控制平面可以运行在独立的集群,也可以运行于服务集群。由 CRD、Operator Manager 、Cluster Connector 和 Pipy Repo 组成。
CRD
</>code
CRD:ClusterConnectorProxyProfile
</>code
ClusterConnectorProxyProfile
Operator Manager
Operator Manager 是控制平面的核心,主要提供如下功能:
- 管理控制平面的 CR 和组件:管理 Cluster Connector 和完成 Pipy proxy 的 注入。
- 数据汇总技术:接收Cluster Connector 上报的工作负载地址等信息并汇总转换成服务注册信息后写入到组件 Pipy Repo 代码库中。
- 初始化工作:这里说的初始化主要是指服务对应的代码库(Pipy Repo 中介绍)的初始化。
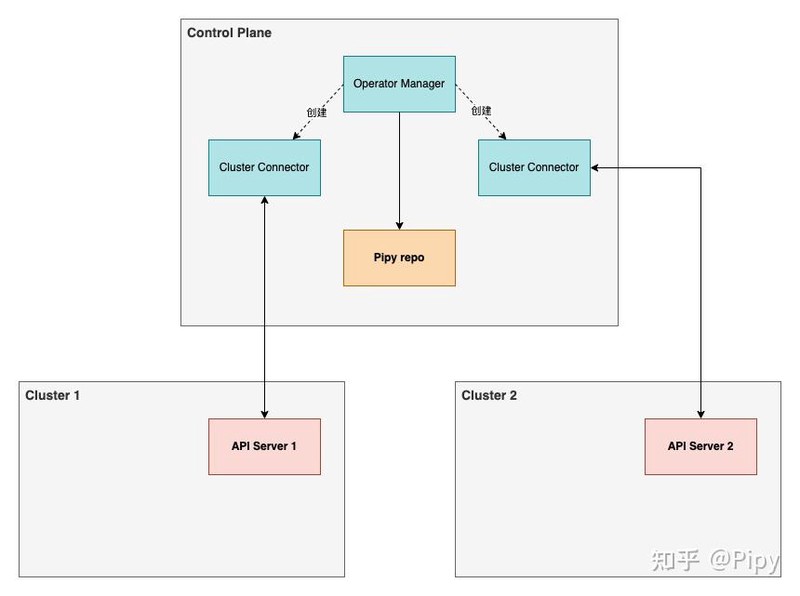
Cluster Connector
每个参与全局流量调度的集群,都有一个与之对应的 Cluster Connector,简单可以将其理解成各个集群的代理。Cluster Connector 通过指定的配置与各集群的 API Server 通信,监控 Endpoint、Service 等的变更。将数据上报到 Operator Manager。
</>code
ClusterConnector
Pipy Repo
Pipy 有两种工作模式:repo 和 worker 节点。
当我们不指定任何脚本启动 Pipy 时,Pipy 会工作在 repo 的模式,将代码库(Pipy 工作时使用的配置和脚本,我们统称为代码库,codebase)以树形的结构(可以理解为文件系统)存储,这些内容以 key-value 的形式存储在内容中,也支持文件系统、LevelDB 等支持化存储。
在跨集群调度的方案中,主要有三种类型的代码库:ingress、egress 和 服务。其中服务类型的代码有基础代码库和各服务的独立代码库。每个集群在 Pipy Repo 中都有各自的三种类型代码库。
运行为 worker 节点模式的 Pipy 可以连接到 Repo 拉取代码库,并保持同步。
在之前的文章 Pipy Repo 入门中我们曾经详细介绍过,可以参考那篇文章获取更多内容。
数据平面
数据平面由 Pipy 组成,Pipy 是面向云、边缘和 IoT 的可编程网络代理。具有灵活多变、快、小、可编程、开放的特性。
在数据平面 Pipy 可以作为 ingress、egress 和 sidecar 三种方式部署,从 Pipy Repo 同步对应类型的代码库。
- ingress: 接受集群外的流量,根据配置将流量调度到对应的工作负载。
- egress:将本集群的流量调度到其他的集群,发送到其他集群的 ingress。
- sidecar:负责本集群流量调度,对于调用其他集群服务的流量有两种方式:一种是使用 egress 来完成;另一种是由 sidecar 直接将流量发送到其他集群的 ingress。
实际上不管是 ingress、egress 还是 sidecar,都是从代码库中获取 service => endpoint 的映射关系。区别在于 endpoint 是本集群的 Pod IP,egress 的地址、或是其他集群的 ingress 地址。
作为不同类型的部署,Pipy 通过编程的方式提供一致的流量管理。之前发布也发布了系列的教程,大家可以参考教程了解 Pipy 的可编程特性。
操作
服务注册
Cluster Connector 连接至各个集群的 API Server 并监测 Service 和 Endpoints 的变更,并将变更信息上报到 Operator Manager。
Operator Manager 将收集的服务注册信息,汇总计算转换成 Pipy 代码库的配置,通过 Pipy Repo 的 REST API 更新到各集群对应代码库中。
服务的注册信息简单来说 service => endpoint 的映射,对于不同类型的数据面实现,映射的地址也各不相同。
对于服务的本地实例,地址是 Pod IP;其他集群的实例,可以使用本地 egress 地址或者其他集群的 ingress 地址。
服务发现
以 Pipy worker 节点模式运行的数据面,连接到 Pipy Repo 同步代码库,从代码库中获取服务的注册信息。
流量拦截
流量拦截有以下几种方式: 。
</>code
0.0.0.0:8080127.0.0.1:8080podip:8080
流量拦截的方式不过多展开,
策略执行
在完成一系列的操作之后,处理流量时就可以执行配置的策略,比如:
- 就近路由策略:优先选择同一节点的路由(比如 flannel cni,可以通过 10.x.x.0 来判断),或者同一集群的路由。
- 负载均衡:可以使用全局默认的负载均衡算法,也可以针对某些服务使用指定的其他算法。
以上这些都可以通过编程的方式在 js 脚本中实现,新增或者更新策略逻辑无需更新二进制文件,仅需更新代码库中的脚本即可,工作节点的 Pipy 会自动完成更新。
可用的策略也不只这两种,比如金丝雀发布、限速、黑白名单等等服务治理的内容,不在本方案的讨论范围内。
总结
这次我们介绍了如何通过 Flomesh 来解决跨集群的流量调度难题,主要介绍了各个组件功能以及服务注册、发现的实现原理。
当前多云多集群愈演愈烈,不管出于何种考虑实施多集群的方案,跨集群的流量调度都是绕不开坎。Flomesh 使用统一的数据平面 Pipy 提供一致的流量管理,借助 Pipy 的可编程进行灵活的功能扩展和系统集成;低资源的特性,也不会有成本的大幅提升;支持多种平台和包括 x86、ARM、RISC- V 在内的多种架构,可轻松实现云、边一体的流量调度。

