
美国心脏协会(AHA)旗下的期刊每年会收到超过20000份投稿稿件,在这些提交的稿件中,使用的统计分析方法和复杂程度上各不相同,从简单的描述性统计(例如,计数和频率)到复杂的建模(例如,多因素回归,倾向性评分,工具变量,生存分析,风险预测模型)和Meta分析等。大多数提交的原始稿件在发表前都将由至少1名统计审稿人或统计编辑进行审核。
为了更好的指导统计审稿人确定研究数据是否进行了适当的分析,为作者在提交的论文中报告统计分析内容提供指导,并帮助读者理解研究设计和分析结果,提高读者体验,AHA科学出版委员会组建了一个专家工作组,共同制定了一套统计报告建议指南《Recommendations for Statistical Reporting in Cardiovascular Medicine》,共分为12个部分,小咖将分几期内容为大家进行具体的介绍,希望能给大家一些指导。


链接:
1. 通用标准
2. 观察性研究:诊断试验和验证
3. 观察性研究:临床预测模型
4. 统计遗传学
5. 随机对照试验
6. 系统综述和Meta分析
7. 生存分析
8. 贝叶斯统计方法
9. 缺失数据
10. 相关数据
11. 协变量调整和倾向性评分
12. 把握度和样本量
第一部分:通用标准
1.1 现有的报告指南
AHA推荐根据不同的研究类型,利用现有的报告规范指南进行报告。
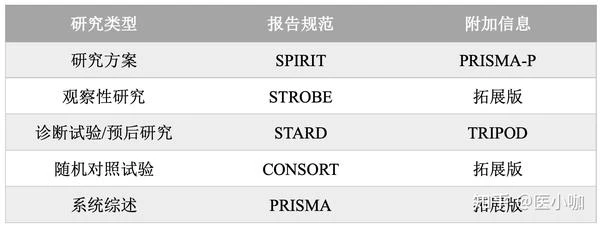
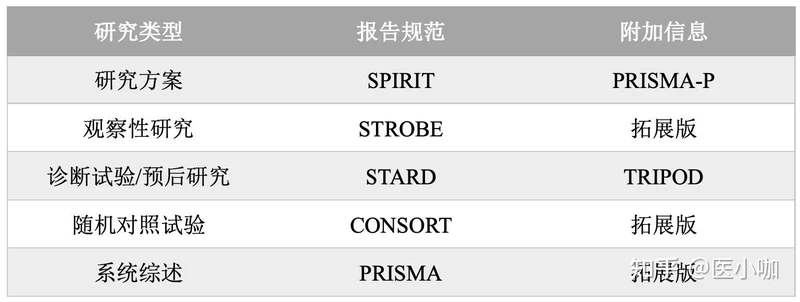
1.2 方法学注意事项
1.2.1 研究人群
研究人群必须进行详细的描述,包括入选日期、招募地点、研究人群是如何被选择的,并报告完整的纳入和排除标准。AHA强烈建议使用流程图来描述最终研究人群纳入和排除的细节。
1.2.2 统计学方法
统计方法应提供详尽的说明,包括使用的模型、比较或检验的方法,要提供足够的信息以确定使用的是哪种方法。许多论文中对于统计学方法的描述都比较模糊,例如“连续变量采用t检验或Wilcoxon检验进行分析”,这种描述不足以让审稿人了解哪些变量使用了哪种检验方法来获得相应的P值。如果在统计学方法中无法完全描述清楚,那么建议可以在表格或图形的下面采用脚注的形式进行标注说明。
1.2.3 可视化
对于数据的准确表达,AHA更推荐使用图形而不是总结性的描述,例如可以描述为:组间均值比较采用条图的形式。后续对图形部分会有更详细的介绍。
1.2.4 分类变量
分类或有序变量不能作为连续变量来进行分析,尤其是有序分类变量。
1.2.5 连续变量
连续变量在临床使用中要符合临床实际,易于解释,必要时应进行一定的转换。例如,通常很难解释年龄增加1岁或血压增加1mmHg的OR或HR,建议以年龄每增加10岁或血压每升高10mmHg的风险变化来衡量更有意义。
1.2.6 关联强度
当变量在不同的尺度上时,避免根据变量的效应大小对变量的关联强度进行排序。例如年龄每增加10岁的OR值为1.10,而性别的OR值为1.15,这并不意味着性别比年龄更能预测结局。如果研究人员希望对变量进行排序以确定最有力的预测因素,就必须使用一种标准化形式将变量放在相同的尺度上进行比较。
1.2.7 P值
报告精确的P值而不是仅用符号来描述显著性,例如P<0.05,类似的写法并不规范。
通常P值报告2位有效数字的精度是较为合适的,除非当P<0.01,此时可以仅报告1位有效数字,例如应写成P=0.002,而不是P=0.0021。
建议要同时报告效应值及其可信区间CI,而不仅仅是单独一个P值。
如果P值非常小,可以报告为P<0.001,如果P值非常接近于1,则报告P>0.99,而不是P=1.00,除非P就是1。
1.2.8 多重比较
对于多重比较的校正虽然仍存在争议,但主要取决于研究目的和研究假设。如果一篇研究中包含多个假设检验,作者要么必须明确说明没有对多重比较进行校正,要么就要明确指出用于解释多重比较的方法。
1.2.9 统计推断
研究人员应该用恰当的语言去描述统计推断结果,例如假设检验P值高于所选的α水平,那么就推断组间没有差异,这种说法是不准确的。具体的描述方法可以参考如下网站:https://discourse.datamethods.org/t/language-for-communicating-frequentist-resultsabout-treatment-effects/934
1.2.10 预先注册登记
AHA鼓励在研究实践的过程中对统计分析计划进行预先注册登记,这在临床试验中是非常常见的的,越来越多的研究人员开始对统计分析计划进行更广泛的注册登记。
1.2.11 共享数据或代码
共享研究数据可能并不可行,但对于研究团队来说,共享用于数据统计分析的代码通常是可行的,如果他们愿意通过分享代码向审稿人清楚地说明实际做了哪些分析,则可以极大地促进统计审查。
1.3 数据可视化
1.3.1 完整性
图形应该有标题,坐标轴应该有标签,同时应提供测量单位。
如果采用符号或颜色传达含义,则应提供图例,最好是在图形本身中,而不是在附带的文本中。
对于变异度或离散度的表达,如误差条或可信区间的阴影区域,应在图中显示或列入表内。对于临床数据,通常推荐标准差(SD)而不是标准误(SE),因为标准差反映的是研究数据内的变异,而标准误是对总体均值估计的不确定性进行量化。
1.3.2 信息性
图形应最大限度地提供有关数据分布的信息。
有的图形是对数据进行总结性的描述,以条形图为例,可能会隐藏潜在的重要信息,例如多峰性、样本量和异常值,当样本量较小时,这个问题就更为突出,因为截然不同的数据分布可以在同一条形图上保持一致。
多种图形组合可以将单个数据点覆盖到数据的箱图或小提琴图上表示,这样读者就可以判断数据是如何分布的。
1.3.3 真实性
在决定显示什么数据以及如何表示它们时,可以有很多选择,应该避免选择采用夸张表现的做法来描述潜在的趋势,例如选择数据非代表性的部分,或截断坐标轴以夸大组间的差异或线性趋势的变化。
图形对数据的描述应该与完整数据真实分析的结果相一致。
对于伴随有统计假设检验的图形,请注意仅显示P值和图形是不够的,还应提供适当的数据统计汇总的结果,例如各组均值和标准差,组间平均差异及其可信区间等。

