第 18讲:高并发数据结构在 Instagram 与 Twitter 中的应用 · 数据结构精讲:从原理到实战 · 看云
你好,我是你的数据结构课老师蔡元楠,欢迎进入第 18 课时的“高并发数据结构在 Instagram 与 Twitter 中的应用”学习。
在如今的计算机系统设计中,有很多的应用已经不再局限于在单机环境下运行了,这些应用会将本身或者底层的存储本身部署在分布式环境中,像是数据库的分片(Sharding),或者是将数据部署到分布式环境下的多台机器集群中,从而达到负载均衡。那我们今天就一起来看看,数据结构在分布式环境应用中扮演着怎么样的一个角色。
我们在第 05 课时中,学习了哈希函数的本质,现在一起回顾一下。哈希函数的定义是将任意长度的一个对象映射到一个固定长度的值上,而这个值称作哈希值。
哈希函数一般有以下三个特性:
* 任何对象作为哈希函数的输入都可以得到一个相应的哈希值;
* 两个相同的对象作为哈希函数的输入,它们总会得到一样的哈希值;
* 两个不同的对象作为哈希函数的输入,它们不一定会得到不同的哈希值。
哈希函数其实是在解决分布式环境部署的一个重要算法,我们就以把数据部署到分布式环境机器集群为例,来说明一下它的重要性。
#### 服务器部署例子
假设现在维护着一个应用,这个应用在同一个时间段会有大量用户读取数据这样的一个场景。为了缓解服务器的压力,我们决定将数据分别存储在 3 台不同的机器中,这样就可以达到负载均衡的效果。
那要怎么样将数据均匀地分发到不同机器中呢?最简单的一种哈希函数设计就是将所有的数据都事先给予一个数字编号,然后采用一个简单的取模运算后将它们分发出去。取模运算这样的哈希函数是指根据机器节点的数量,将数据的编号对机器节点的数量做除法,得到的余数就是这个数据最终保存机器的位置。
下面我们来详细说明。现在客户需要检索以下三个数据,它们的数据编号分别为 7737、8989 和 8338。因为前面已经决定了需要 3 台机器来存储这些数据,所以哈希函数所要做的运算就是用数据编号除以 3,得到的余数就是存储数据的机器编号,也就是数据编号 %3 运算,结果如下表所示:
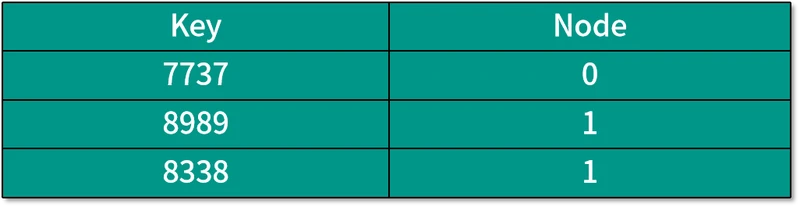
这种方法非常的直观和简单,但是却有一个致命的缺点,那就是当我们改变机器数量的时候,有很多数据的哈希运算结果将会改变。这种情况发生在,当我们的服务器压力过大想要扩充服务器数量的时候;又或者是服务器数量已经很充足,公司想要节省开支而减少服务器数量的时候。
我们来举个简单的例子看看当发生这种情况时后台的数据会有什么样的变化。
当服务器数量还是 3 的时候,编号在前 10 的数据,经过哈希运算后保存数据的机器如下表所示:
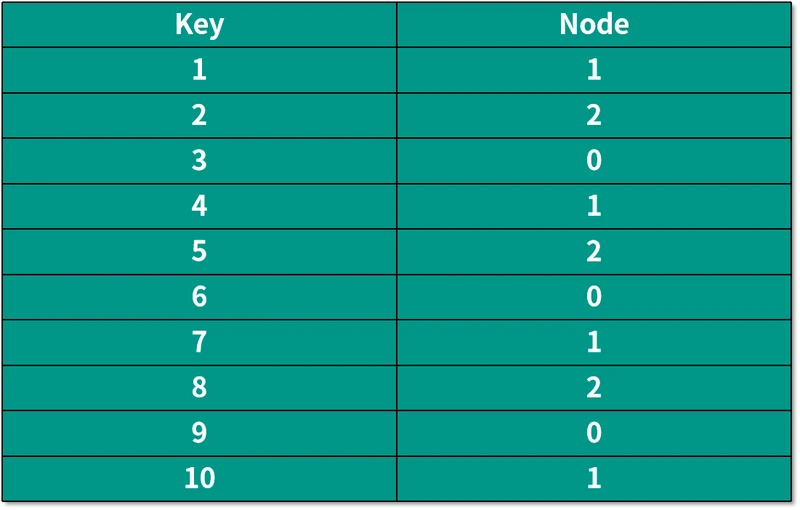
如果我们需要增加一个服务器,也就是机器数量变成 4 的时候,编号在前 10 的数据,经过哈希运算后保存数据的机器如下表所示:
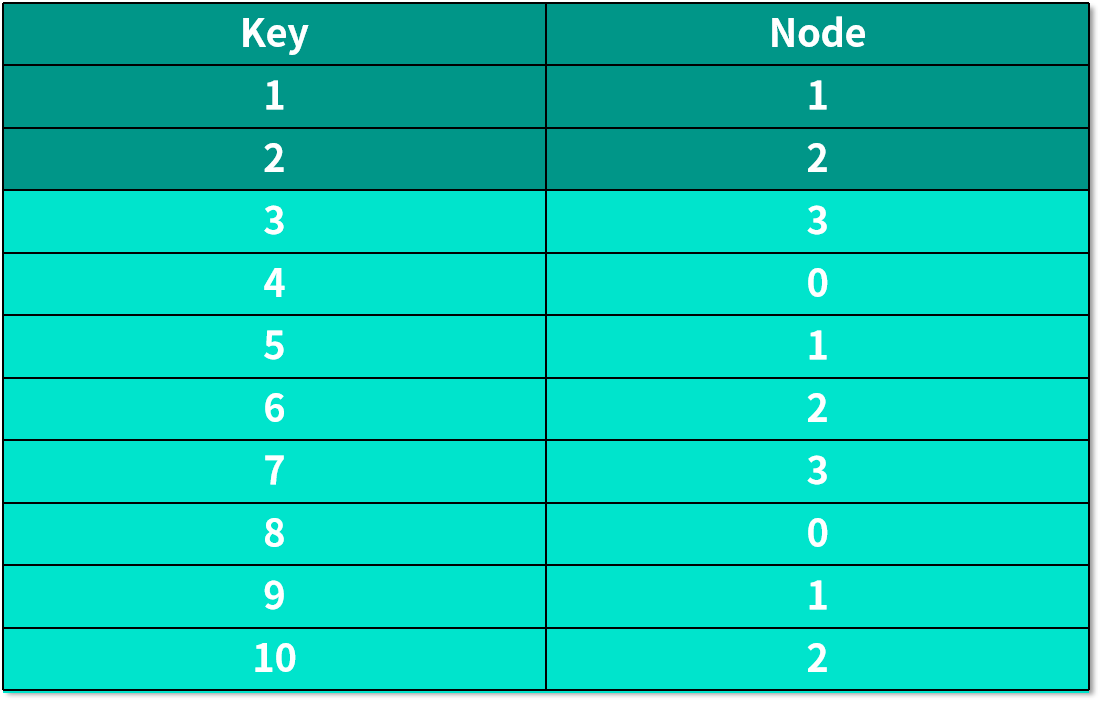
背景被标蓝的行,表示保存这个数据的机器发生了变化。这也就意味着:应用的后台需要重新将数据分配一遍,而如果有用户在重新分配数据的这段时间刚好想要访问这些数据,比如说,用户想访问 key 为 3 的数据,到了 3 号服务器,因为数据还未被重新分配,实际保存这个数据的服务器是 0 号服务器,就会造成想要访问的数据不存在,这时候用户只能将所有服务器遍历一遍,看看哪一个服务器保存了这个数据。
这样的缺点在数据量十分庞大又或者服务器非常多的时候,对应用是十分不利的。为了克服这个缺点,我们需要用到另外一种算法,那就是“一致性哈希算法”。
#### 一致性哈希算法的定义
一致性哈希算法(Consistent Hashing)是 David Karger 在 MIT 于 1997 年提出的一个概念,该算法可以使哈希算法的计算独立于机器的数量。那么下面我们就来看看一致性哈希算法是如何运作的。
一致性哈希算法会将计算出来的哈希值映射到一个环中,为了方便说明,因为一个圆环是 360 度,所以这里采用取模 360 的计算方式将哈希值映射到环中,也就是说在计算出每个数据或者服务器的哈希值 H 后,我们采取 H % 360的计算方式来得到这个数据或者服务器在圆环中的位置。当然在实际应用中,你也可以采用其他的计算方式将哈希值映射在环上。

一致性哈希算法通常涉及了以下 3 个步骤:
* 计算出分布式环境下机器对应的哈希值,然后根据哈希值将其映射到圆环上,对于计算分布式环境下机器的哈希值,我们一般根据机器的 IP 地址来进行计算;
* 计算出数据的哈希值,然后根据哈希值将其映射到圆环上;
* 把映射到圆环上的数据存放到在顺时针方向上最接近它的机器中,如果机器映射在圆环上的值和数据映射在圆环上的值相同,则将数据直接存储在该机器中。
#### 一致性哈希算法是怎么工作的
好了,那现在我们用实际的例子来看看一致性哈希算法是如何工作的。
我们还是按照一开始将数据部署到 3 台机器的情况来讲解。假设三个机器映射到环中的位置如下表所示:
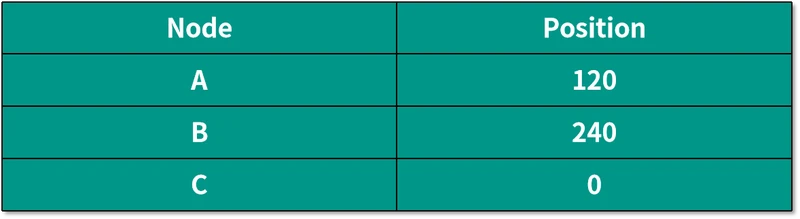
数据映射到环中的位置如下表所示:
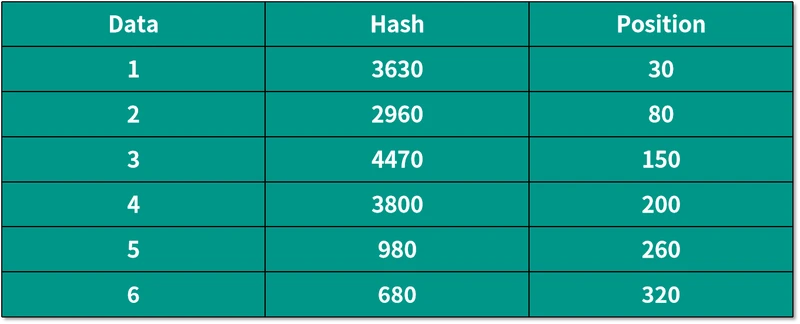
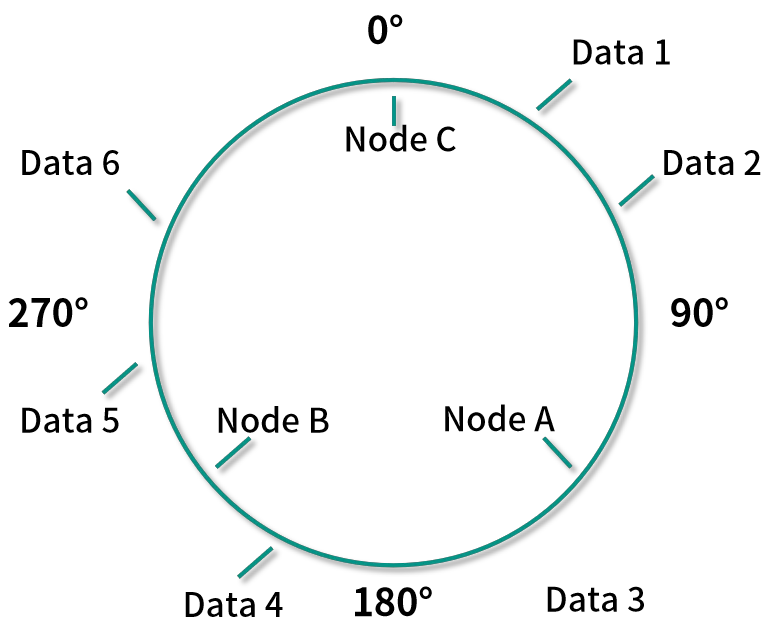
根据上面的算法,将所有映射好的数据按顺时针保存到相应的机器节点中,就是说将 Data 1 和 Data 2 放到 Node A 中,Data 3 和 Data 4 放到 Node B 中,Data 5 和 Data 6 放到 Node C 中。
如果这个时候我们需要添加一个新的机器 Node D,映射到环上后的位置如下所示:
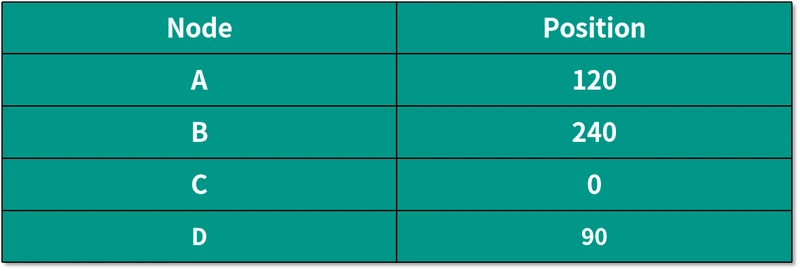

根据算法,这时候只有 Data 1 和 Data 2 需要重新分配到 Node D 中,而不是像之前普通的哈希算法,需要将几乎所有的数据都重新分配一遍。
一致性哈希算法,可以将增加或者删除一个机器导致数据重新分配的平均时间复杂度从 O(K) 降到 O(K / N + log(N)),这里的 K 代表数据的个数,N 代表机器的个数。当然了,一致性哈希算法还涉及到很多其他问题,比如数据是否平均分配到了不同的机器中,想深入了解的话建议看看 Karger 的这篇论文。
我们在第 08 讲中,曾经讲过 Facebook 自己做了一个名叫 Mcrouter 的服务器出来,可以将不同的数据请求导向不同的 Memcache 机器上。同样的,Facebook 旗下的 Instagram 应用,有着大量的照片和视频需要保存在缓存中,从而加速数据读取速度,而管理这些 Mcrouter 服务器背后的算法正是一致性哈希算法。
#### Twitter 如何利用 B 树和 Redis 实现超大规模 Timeline
在最后我还想和你介绍另外一个在北美热门的应用软件 Twitter 所使用到的数据结构。Twitter 作为一个社交平台,同时拥有着高活跃度的用户,用户读取数据的低延时性是必不可少的,所以缓存成为了平台中的重要一环。
在 Twitter 里面的一个相当重要的功能就是 Timeline 时间线功能。Timeline 功能会将社交网络中的各种内容展示给用户,用户通过不停下拉来获取最新的内容,这也是一个典型的读操作远远大于写操作的应用场景。实际上,Timeline 里面保存的并不是 Twitter 推文的实际内容,而且对应推文的一个 ID,这些 ID 对应的实际内容被保存在了 Redis 缓存中。
通过之前的学习,我们知道 Redis 本质就是一个哈希表,哈希表是无法对数据进行排序的,那有什么办法可以解决这个问题呢?如果你还记得第 12 讲里面 LSM Tree 的本质,就明白了这个问题是通过 B-Tree 来解决的。没错,Twitter 也是通过在 Redis 中维护 B-Tree 来达到对一个用户 Timeline 中推文时间的排序。


