
Facebook这篇Embedding召回的论文,之前已经有几篇文章涉及过了,分别是《Embeding-based Retrieval in FaceBook Search》、《是"塔"!是"塔"!就是"它",我们的双塔!》和《负样本修正:既然数据是模型的上限,就不要破坏这个上限》,有兴趣的可以回顾一下。
回顾

在以上几篇文章中,模型结构没啥好说的,简单的双塔,两边塔的输入都是文本特征、社交特征和位置特征,其中社交特征和位置特征是他们在实验中发现对效果提升比较好的两种特征。
01
核心亮点
这篇工作的两个核心亮点是hard negative mining和embedding ensemble。
Hard negative mining是指,他们发现如果将随机负样本这种比较easy的样本与上次召回中排名101-500名的比较hard的样本以100:1的比例去训练模型(为什么是101-500?),得到的效果会比较好。
Embedding ensemble是指,可以将不同负样本训练得到的模型做融合来进行召回。融合的方式可以是相似度结果的直接加权或者是模型的串行融合,比如先用easy负样本训练模型进行初步的筛选,再用hard负样本训练模型进行最终的召回。
另外他们还提到虽然使用unified的特征,就是输入中包含社交特征和位置特征,来进行召回效果会比较好,但是召回结果在一定程度上也会损失文本的匹配,因此也可以先通过只输入文本特征的模型来做筛选再用输入unified特征的模型来召回,这样可以保证文本的匹配。
02
系统模块
对于一个搜索引擎而言,往往由两个层构成,一个叫召回层,另一个叫排序层。召回层的目的就是在低延时,低资源利用的情况下,召回相关的documents。排序层就是通过很复杂的算法(网络结构)把和query最相关的document排序到前面。论文的题目,简单直白的告诉了大家,用embeding 表示query和document来做召回。
论文提到,召回的难点,主要体现在候选集合非常庞大,处理亿级别的documents都是正常操作。不同于面部识别召回,搜索引擎的召回需要合并字面召回和向量召回两种结果。"脸书"的召回,还有其他难点,"人"的特征,在"脸书"的搜索尤其重要。
同时,《Embeding-based Retrieval in FaceBook Search》一文中,也通过对Query处理、索引模块、召回模块、排序模块等做了一一的讲解。对该部分细节有兴趣的同学 ,可以查看下原文。
负样本的艺术
最近又重新翻了翻这篇论文后,对该论文对负样本的应用又有了一些新的感悟。本文主要在样本构造方面,来聊一聊负样本的艺术。
“数据和特征决定了机器学习的上限,而模型和算法只是逼近这个上限”。有过机器学习经验的人都会知道特征对于解决机器学习问题的重要性了,在y=ax+b的公式里,特征解决了x的问题,而y的问题即是样本的问题,如果定义label,也同样重要。
01
曝光未点击负样本
在召回阶段,我们可以常会沿用排序阶段的思路,使用曝光且点击的为正样本,曝光未点击的为负样本。
这种方法我们在线下使用FM依旧可以有AUC 0.8+的水平,但线上提升却只有微微一点。那么为何线上线下造成了这样的不一致呢?
其一,我们来思考一下,曝光未点击,是怎么来的呢?
曝光未点击的数据,其实也是我们的模型在进行各种排序筛选之后,认为大概率命中了用户的兴趣才曝光给用户的,也就是说,使用的负样本是经过排序处理后的用户最喜欢的TopK个Items,相比之下,这些item对于召回来说,这些负样本很大概率上是召回的正样本了,则此时使用的样本集训练出的模型只学习到了用户可能喜欢的中,区分最喜欢和可能喜欢的信息,而对于用户不喜欢的item却没有学到。

其二,在实践中,尤其是很多大型的平台,用户和商品都是亿级别的,对这种级别的数据进行排序不仅会耗费大量的计算资源,而且还要等很久的时间,所以大家都会选择采样观察指标。很多时候大家会选择采样个无关的商品然后加上相关的商品再去计算指标,其实只需要保证采样之后计算得到的指标和我们的全量数据计算得到的指标是保证相对大小的,换言之,这里违反了一条机器学习里的基本准则,线下线上数据样本分布的一致性。
02
随机负样本
在Facebook的论文中,实验了两种负样本的构造方法,论文提到用未点击的曝光作为负样本训练出来的模型非常糟糕,在互联网工作了这么多年,我们在实践中也发现了这个问题。原因是这部分负样本太hard了,这么hard当然要放到精排去学,召回任务最重要的是快速把和query相关的documents拉出来。如果召回阶段就能把曝光未点击的过滤掉,那还要精排干嘛呢?
第二种负样本方法就是随机选择负样本,使用为用户召回的item中未曝光的部分的随机采样,对热门和非热门以热度来进行概率加权,从而实现热度采样,看到这里你也许会感觉似曾相识,没错这里跟Word2Vec中的负样本采样方法是同理的。
实验结果表明,随机采样的负样本比“曝光未点击”的负样本的线上效果要好很多。其实不难理解,线上实际召回时,大部分的item是模型没有见过的,随机的负样本抽样很贴合这种线上实际情况。
从Bias的角度,user和item之间未被发现到的交互可以归因于两大原因:1)商品与用户兴趣不匹配;2)用户不知道该商品。因此,无法区分真正的负反馈(如曝光但不感兴趣)和潜在的正反馈(如未曝光)将导致严重的Bias。
在大多数情况下,一小部分受欢迎的item占了大多数用户交互的比例。当对这些长尾数据进行训练时,该模型通常会给热门项目的评分高于其理想值,而只是简单地将不受欢迎的item预测为负值。因此,推荐热门item的频率甚至比数据集中显示的原始受欢迎程度还要高。
03
Hard增强负样本
Hard样本这个说法来自图像的分类任务,在搜索推荐系统的召回中没有类别的概念,无法直接应用图像的Hard样本挖掘方法。Facebook在论文中尝试了两种Hard样本挖掘的方法:Hard负样本挖掘和Hard正样本挖掘。
Facebook在论文中发现很多时候同语义召回的结果,大部分都是相似的,而且没有区分度,最相似的结果往往还排不到Top的位置,这就说明之前的训练样本构造方式有问题,导致模型学习的不够充分。所以就想到了对应了解决方案,把和Positive Sample很近的样本作为负样本用于训练,通过这种方式模型就能学到这种Hard样本的区分信息了。
Hard负样本挖掘
论文提到,他们发现top-K召回结果大部分是同文本的,也就是说模型并没有充分利用社交特征。这主要因为随机负样本对于模型而言,因为和query文本完全不同,模型太容易学偏,认为文本一样就是需要召回的。
为了能使模型对相似的结果能有所区分,所以我们可以找到那些embeding很近,但实际上是负样本,让模型去学。
一种方法是在线hard负样本挖掘,这个思路就是in-batch负采样,在一个batch内,有n个相关的query和document,对于任意一个query,其他的document都是它的负样本,但是由于每个batch也是随机产生的,in-batch内负采样并不能获得足够的hard负样本。所以就有了离线hard负样本采样。
论文提到,在实验中发现,简单用hard负样本,效果是比用随机负样本要差的,主要原因是hard负样本需要非文本的特征区分,而easy负样本主要用文本特征区分,因此需要调整采样策略。论文还提到一点,hard负样本取排序模型排在101-500效果最好(所以其实要用semi-hard的样本),而且hard负样本需要和easy负样本混合在一起用。
Hard正样本挖掘
正样本选择相关度最高的,即用户点击过的样本和相似度高的潜在正样本作为Hard正样本。
这里做法和百度的Mobius中的做法很是相似了。
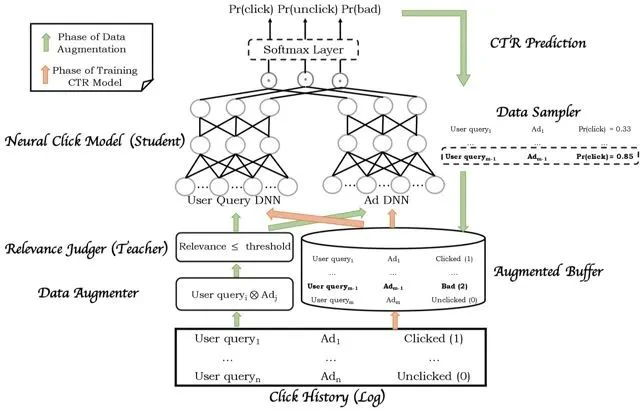
整个框架分为两个阶段,数据增强阶段是绿色箭头的部分,采样并利用样本中的用户请求与广告构造出更多样本,教师网络计算相似度后将低相似度的样本输入学生网络去预测CTR,通过采样的方式得到高CTR低相似度的样本存入buffer,这类样本我们称之为Badcase。
小结
在召回问题中,用“曝光未点击”作为模型的负样本的一系列问题,其根源在于没有很好地理解问题,只是从经验的角度给出了解法,而这种解法不能算错,至少在线上反馈的层面上是有意义的,也具备一定的表征能力。
究其原因,曝光未点击的样本,一方面,它是经过了之前模型层层筛选得到的,至少在之前的模型中,模型判断的是用户对该部分item是具有兴趣的;另一方面,经过了线上的时间曝光之后,用户并没有点击,而这个不点击只是在Feed流中的相对的未点击。
因为位置偏差告诉我们,用户倾向于与位于推荐列表中较高位置的item进行交互,而不管这些item的实际相关性如何,因此交互的item可能不是高度相关的。
参考资料
- https://arxiv.org/pdf/2006.11632.pdf
- 推荐系统Bias大全
- 是不是你的模型又线下线上不一致啦?
- https://zhuanlan.zhihu.com/p/339116577
- 就是这么"硬"!召回系统就该这么做!

